想玩龙虾OpenClaw?手把手教你一步步安装跑通

最近龙虾OpenClaw真是火爆了,有很多小伙伴都来问阿赞,该怎么安装一个自己的龙虾?

我们看一下最终的样子,安装指南来了!
读完本篇文章,你可以学会:在自己的电脑上安装一个自己的龙虾,并用飞书来直接跟他聊天,完全不需要任何编程基础,纯小白也能轻松上手!
准备工作
首先,你需要一台可以连接互联网的电脑
Windows、MacOS、Linux 都可以
有不少已经上网搜索过龙虾的小伙伴会问:Windows、MacOS、Linux 哪个系统更适合安装龙虾? 我是否应该买一台Mac Mini?
在阿赞的角度来看:MacOS 肯定是独一档的好
因为有着更好的稳定性,更强的性能,更低的功耗,让Mac Mini成为最适合龙虾的机器
但是其他系统也完全可以使用,如果不是重度依赖龙虾工作,你完全没有必要额外去买一台Mac Mini,在现有的电脑上安装使用足矣。
其次,你需要一个大模型的API接口
你可以买任何你觉得好用的大模型API接口,OpenAI、Anthropic、国内的模型厂商都可以
如果你没有预算,完全可以使用免费的模型接口,或者你有比较不错的显卡,那么你完全可以选择在本地部署一个开源模型,来当做龙虾的后端引擎。
开始安装
我相信绝大多数小伙伴都有windows电脑,所以我们以Windows系统为例,来介绍一下安装的步骤。
MacOS 和 Linux 的安装步骤基本上是一样的,唯一的区别就是第一步安装 Docker 的方式不太一样,后续的步骤完全一样。
第一步,安装docker
你可以在下面这个地址找到docker的安装教程,这里我不再赘述
https://www.runoob.com/docker/windows-docker-install.html
安装并启动完成之后,可以看到docker的界面了
打开一个命令行窗口,输入 docker version 来验证一下是否安装成功
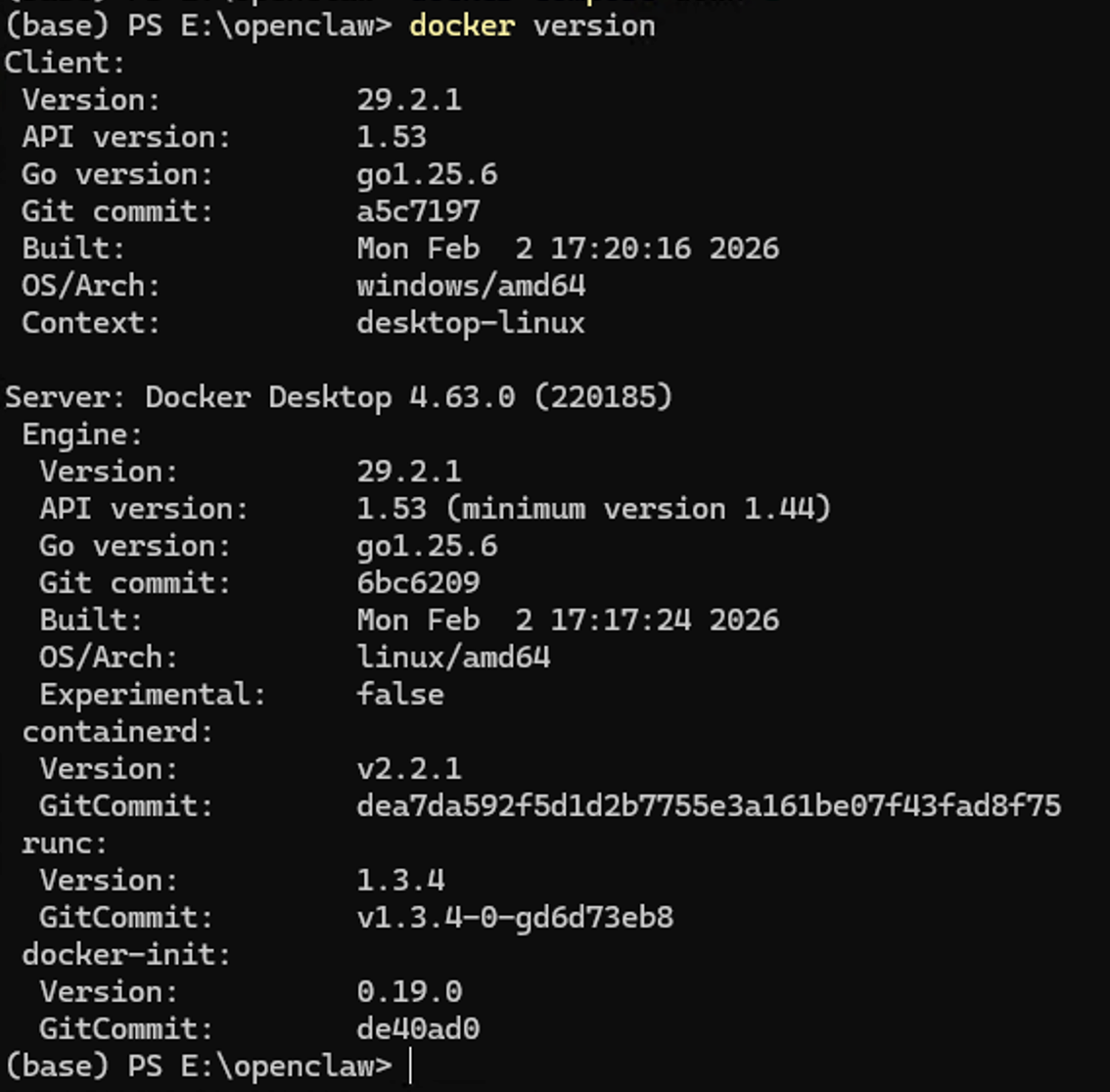
看到如上界面后,就表示docker安装成功了,我们就可以进入下一步了。
第二步,下载龙虾docker镜像
这里我们使用了一个已经集成好了国内各种聊天软件的龙虾
Github仓库地址如下,感兴趣的小伙伴可以阅读一下,不感兴趣的直接按照我们下面的步骤来操作 https://github.com/justlovemaki/OpenClaw-Docker-CN-IM
打开一个命令行窗口,输入下面的命令来下载这个龙虾的docker镜像
docker pull justlovemaki/openclaw-docker-cn-im:latest
如果你没有科学上网的条件,那么大概率上面这个镜像下不下来,没关系我这里也准备了一个国内网络友好的镜像地址
docker pull registry.cn-hangzhou.aliyuncs.com/dongfangzan/openclaw-docker-cn-im:20260309
你也可以在后台私信我回复:龙虾,我已经把这个镜像准备好了

文件下载下来之后,在下载目录,执行下面的命令即可完成导入
docker load -i openclaw.tar
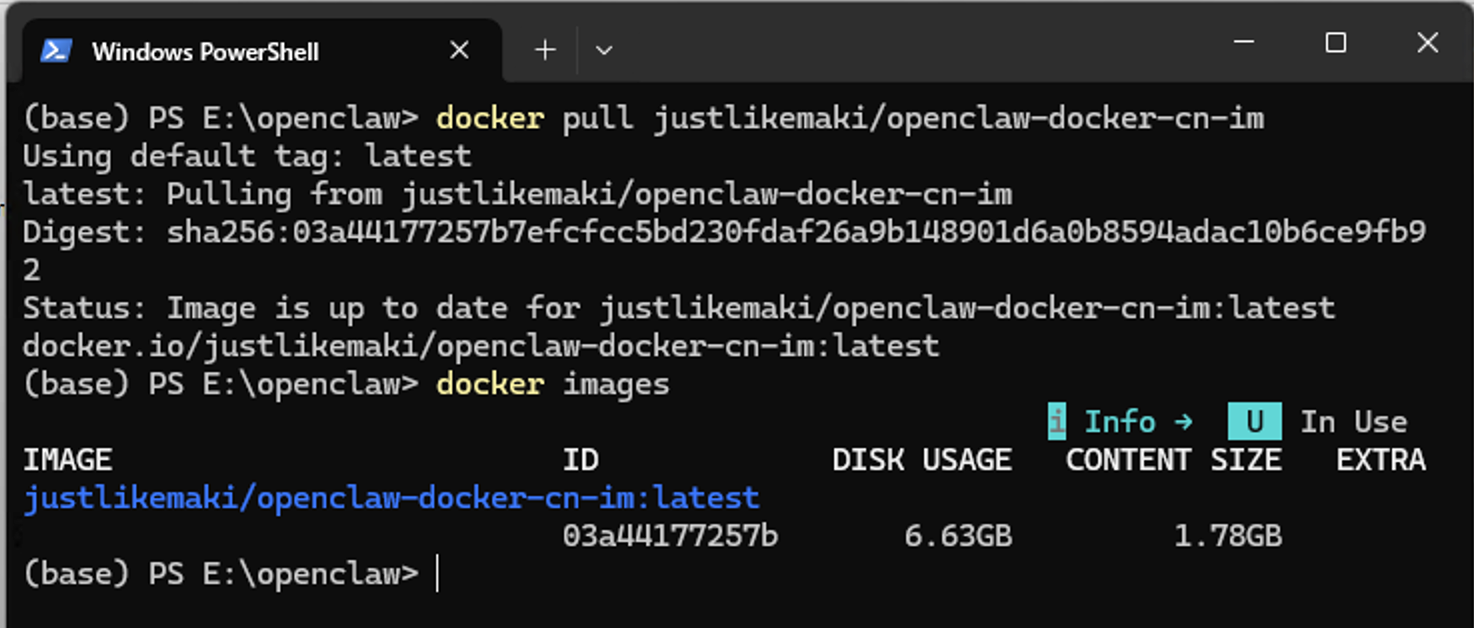
下载完成后,你可以输入下面的命令看到这个镜像
docker images
第三步,启动龙虾
在你觉得合适的地方,创建一个目录来存放龙虾的数据,比如 E:\openclaw-data
这里可以看到,当前目录是空的,我们现在需要创建一个文本文档,命名为 .env
所有的配置文件,你可以关注我的公众号,并在后台回复:龙虾,我已经把所有涉及到的文件都准备好了
把下面的内容,保存进.env文件中,然后我们开始替换掉里面的内容
创建配置文件
# OpenClaw Docker 环境变量配置示例
# 复制此文件为 .env 并修改相应的值
# Docker 镜像配置
OPENCLAW_IMAGE=justlikemaki/openclaw-docker-cn-im:latest
# 模型配置
# 是否自动同步模型配置到 openclaw.json (true/false)
# 如果你手动修改了 openclaw.json 中的模型设置,请将其设为 false
SYNC_MODEL_CONFIG=true
# 提供商 1 (默认)
# 主模型 ID (支持多个,用逗号隔开,第一个将作为默认模型)
MODEL_ID=model id
# 图片模型 ID (可选,留空则使用 MODEL_ID,支持 provider/model 格式)
IMAGE_MODEL_ID=
BASE_URL=http://xxxxx/v1
API_KEY=123456
# API 协议类型: openai-completions 或 anthropic-messages
API_PROTOCOL=openai-completions
# 模型上下文窗口大小
CONTEXT_WINDOW=200000
# 模型最大输出 tokens
MAX_TOKENS=8192
# 提供商 2 (可选)
# MODEL2_NAME=model2
# MODEL2_MODEL_ID=model id1,model id2
# MODEL2_BASE_URL=http://xxxxx/v1
# MODEL2_API_KEY=123456
# MODEL2_PROTOCOL=openai-completions
# MODEL2_CONTEXT_WINDOW=200000
# MODEL2_MAX_TOKENS=8192
# Telegram 配置(可选,留空则不启用)
TELEGRAM_BOT_TOKEN=
# 飞书配置(可选,留空则不启用)
FEISHU_APP_ID=
FEISHU_APP_SECRET=
# 是否启用飞书官方插件 (true/false)
FEISHU_OFFICIAL_PLUGIN_ENABLED=false
# 钉钉配置(可选,留空则不启用)
DINGTALK_CLIENT_ID=
DINGTALK_CLIENT_SECRET=
DINGTALK_ROBOT_CODE=
DINGTALK_CORP_ID=
DINGTALK_AGENT_ID=
# QQ 机器人配置(可选,留空则不启用)
QQBOT_APP_ID=
QQBOT_CLIENT_SECRET=
# NapCat (OneBot v11) 配置(可选,留空则不启用)
# NapCat 反向 WS 监听端口(NapCat 主动连接到此端口)
NAPCAT_REVERSE_WS_PORT=
# NapCat HTTP API 地址(可选,用于主动发送消息)
NAPCAT_HTTP_URL=
# 连接鉴权 Token(与 NapCat 侧保持一致)
NAPCAT_ACCESS_TOKEN=
# 管理员用户 ID,多个用逗号分隔
NAPCAT_ADMINS=
# 企业微信配置(可选,留空则不启用)
# 方式1:单账号(兼容旧格式),会自动同步为 channels.wecom.default
WECOM_TOKEN=
WECOM_ENCODING_AES_KEY=
# 方式2:多账号(Multi-Bot)JSON,支持 bot1/bot2... 独立配置(会与现有配置深度合并)
# 注意:.env 中 JSON 需要写成单行
# 示例:{"bot1":{"token":"t1","encodingAesKey":"k1","agent":{"corpId":"wwxxx","corpSecret":"s1","agentId":1000001}},"bot2":{"token":"t2","encodingAesKey":"k2","agent":{"corpId":"wwxxx","corpSecret":"s2","agentId":1000002}}}
WECOM_BOTS_JSON=
# 工作空间配置(不要更改)
WORKSPACE=/home/node/.openclaw/workspace
# 挂载目录配置(按实际更改)
# OpenClaw 数据目录(包含配置文件、工作空间等所有数据)
OPENCLAW_DATA_DIR=~/.openclaw
# 可选:容器启动用户 UID:GID
# 默认 0:0(root)用于 init.sh 自动修复挂载目录权限,再降权为 node 启动服务
# 如需与宿主机用户对齐,可设置为 1000:1000 或 Linux 上的 $(id -u):$(id -g)
OPENCLAW_RUN_USER=0:0
# Gateway 配置
## 网关 token,用于认证(按实际更改)
OPENCLAW_GATEWAY_TOKEN=123456
OPENCLAW_GATEWAY_BIND=lan
OPENCLAW_GATEWAY_PORT=18789
OPENCLAW_BRIDGE_PORT=18790
OPENCLAW_GATEWAY_MODE=local
# 允许的 Origin 域,多个用逗号隔开
OPENCLAW_GATEWAY_ALLOWED_ORIGINS=http://localhost
# 允许不安全认证(如 http),可选 true/false
OPENCLAW_GATEWAY_ALLOW_INSECURE_AUTH=true
# 危险:禁用设备认证(如在 Docker 环境中无法获取设备信息),可选 true/false
OPENCLAW_GATEWAY_DANGEROUSLY_DISABLE_DEVICE_AUTH=false
# 插件全局控制
OPENCLAW_PLUGINS_ENABLED=true
# 飞书官方插件独立开关(对应 plugins.entries.feishu-openclaw-plugin.enabled)
# 与旧版 feishu 渠道互斥:
# true = 启用 feishu-openclaw-plugin,并自动禁用旧版 feishu
# false = 禁用 feishu-openclaw-plugin,并自动启用旧版 feishu
# 留空表示不覆盖现有配置;若检测到官方插件已有状态,也会自动与旧版 feishu 做互斥处理
FEISHU_OFFICIAL_PLUGIN_ENABLED=
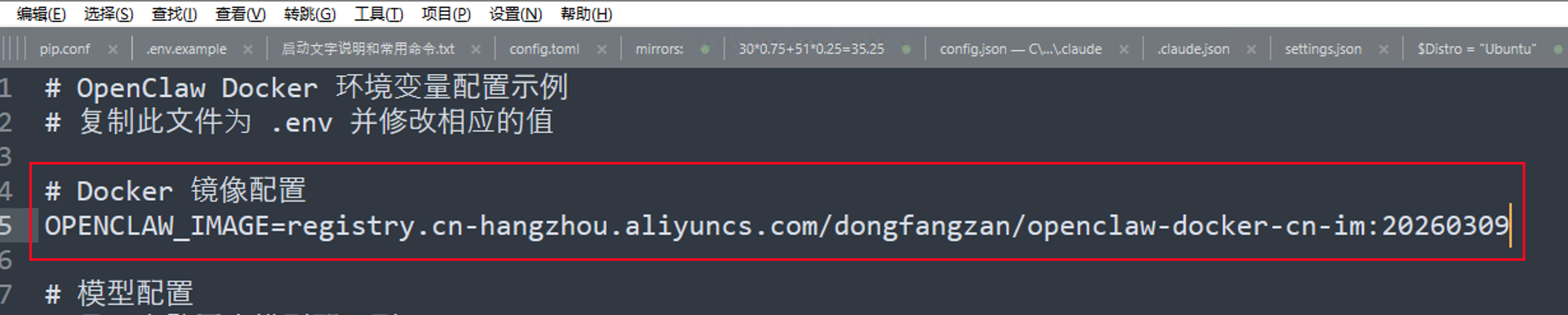
首先需要注意的是,如果在第二步 中下载的镜像是registry.cn-hangzhou.aliyuncs.com/dongfangzan/openclaw-docker-cn-im:20260309
那么你需要把上面.env文件中的 OPENCLAW_IMAGE 的值,替换成 registry.cn-hangzhou.aliyuncs.com/dongfangzan/openclaw-docker-cn-im:20260309
接下来我们需要替换掉模型相关的配置
注意下面这一块内容,你需要把MODEL_ID、BASE_URL、API_KEY 和 API_PROTOCOL 替换成你自己的大模型接口的相关信息
# 提供商 1 (默认)
# 主模型 ID (支持多个,用逗号隔开,第一个将作为默认模型)
MODEL_ID=model id
# 图片模型 ID (可选,留空则使用 MODEL_ID,支持 provider/model 格式)
IMAGE_MODEL_ID=
BASE_URL=http://xxxxx/v1
API_KEY=123456
# API 协议类型: openai-completions 或 anthropic-messages
API_PROTOCOL=openai-completions
# 模型上下文窗口大小
CONTEXT_WINDOW=200000
# 模型最大输出 tokens
MAX_TOKENS=8192
在这个步骤中,我们就需要用到大模型的接口了,如果你还没有的话,可以去购买一个,或者使用本地部署的。
我们需要找到你的API Key 和 API Base URL
这个在为你提供大模型接口的厂商那里都可以找到,通常在控制台的API管理或者密钥管理那里
比如你在阿里云购买了一个Coding Plan的大模型接口,那么就可以按如下进行填写
# 提供商 1 (默认)
# 主模型 ID (支持多个,用逗号隔开,第一个将作为默认模型)
MODEL_ID=qwen3.5-plus
# 图片模型 ID (可选,留空则使用 MODEL_ID,支持 provider/model 格式)
IMAGE_MODEL_ID=
BASE_URL=https://coding.dashscope.aliyuncs.com/v1
API_KEY=sk-xxxxxx
# API 协议类型: openai-completions 或 anthropic-messages
API_PROTOCOL=openai-completions
# 模型上下文窗口大小
CONTEXT_WINDOW=200000
# 模型最大输出 tokens
MAX_TOKENS=8192
然后注意在第78行,现在是OPENCLAW_DATA_DIR=~/.openclaw
需要替换为你在第三步一开始创建的目录 OPENCLAW_DATA_DIR=E:\\openclaw-data\\.openclaw
windows 路径需要使用双斜杠
\\来转义,如果是MacOS 或 Linux 则直接使用单斜杠/即可
替换完成后,保存这个.env文件
可以看到当前目录下目前只有这个.env文件
创建启动文件
接着,再打开一个新的文本文件,命名为 docker-compose.yml
把下面的所有内容,复制粘贴到 docker-compose.yml 文件中进行保存
version: '3.8'
x-openclaw-common-env: &openclaw-common-env
TZ: Asia/Shanghai
HOME: /home/node
TERM: xterm-256color
# 模型配置
SYNC_MODEL_CONFIG: ${SYNC_MODEL_CONFIG}
MODEL_ID: ${MODEL_ID}
IMAGE_MODEL_ID: ${IMAGE_MODEL_ID}
BASE_URL: ${BASE_URL}
API_KEY: ${API_KEY}
API_PROTOCOL: ${API_PROTOCOL}
CONTEXT_WINDOW: ${CONTEXT_WINDOW}
MAX_TOKENS: ${MAX_TOKENS}
# 提供商 2 (可选)
MODEL2_NAME: ${MODEL2_NAME}
MODEL2_MODEL_ID: ${MODEL2_MODEL_ID}
MODEL2_BASE_URL: ${MODEL2_BASE_URL}
MODEL2_API_KEY: ${MODEL2_API_KEY}
MODEL2_PROTOCOL: ${MODEL2_PROTOCOL}
MODEL2_CONTEXT_WINDOW: ${MODEL2_CONTEXT_WINDOW}
MODEL2_MAX_TOKENS: ${MODEL2_MAX_TOKENS}
# 通道配置
TELEGRAM_BOT_TOKEN: ${TELEGRAM_BOT_TOKEN}
FEISHU_APP_ID: ${FEISHU_APP_ID}
FEISHU_APP_SECRET: ${FEISHU_APP_SECRET}
DINGTALK_CLIENT_ID: ${DINGTALK_CLIENT_ID}
DINGTALK_CLIENT_SECRET: ${DINGTALK_CLIENT_SECRET}
DINGTALK_ROBOT_CODE: ${DINGTALK_ROBOT_CODE}
DINGTALK_CORP_ID: ${DINGTALK_CORP_ID}
DINGTALK_AGENT_ID: ${DINGTALK_AGENT_ID}
QQBOT_APP_ID: ${QQBOT_APP_ID}
QQBOT_CLIENT_SECRET: ${QQBOT_CLIENT_SECRET}
NAPCAT_REVERSE_WS_PORT: ${NAPCAT_REVERSE_WS_PORT}
NAPCAT_HTTP_URL: ${NAPCAT_HTTP_URL}
NAPCAT_ACCESS_TOKEN: ${NAPCAT_ACCESS_TOKEN}
NAPCAT_ADMINS: ${NAPCAT_ADMINS}
# 企业微信配置
WECOM_TOKEN: ${WECOM_TOKEN}
WECOM_ENCODING_AES_KEY: ${WECOM_ENCODING_AES_KEY}
# 企业微信多账号配置(JSON 字符串,示例见 .env.example)
WECOM_BOTS_JSON: ${WECOM_BOTS_JSON}
# 工作空间配置
WORKSPACE: ${WORKSPACE}
# Gateway 配置
OPENCLAW_GATEWAY_TOKEN: ${OPENCLAW_GATEWAY_TOKEN}
OPENCLAW_GATEWAY_BIND: ${OPENCLAW_GATEWAY_BIND}
OPENCLAW_GATEWAY_PORT: ${OPENCLAW_GATEWAY_PORT}
OPENCLAW_BRIDGE_PORT: ${OPENCLAW_BRIDGE_PORT}
OPENCLAW_GATEWAY_MODE: ${OPENCLAW_GATEWAY_MODE}
OPENCLAW_GATEWAY_ALLOWED_ORIGINS: ${OPENCLAW_GATEWAY_ALLOWED_ORIGINS}
OPENCLAW_GATEWAY_ALLOW_INSECURE_AUTH: ${OPENCLAW_GATEWAY_ALLOW_INSECURE_AUTH}
OPENCLAW_GATEWAY_DANGEROUSLY_DISABLE_DEVICE_AUTH: ${OPENCLAW_GATEWAY_DANGEROUSLY_DISABLE_DEVICE_AUTH}
OPENCLAW_GATEWAY_AUTH_MODE: ${OPENCLAW_GATEWAY_AUTH_MODE}
# 插件控制
OPENCLAW_PLUGINS_ENABLED: ${OPENCLAW_PLUGINS_ENABLED}
FEISHU_OFFICIAL_PLUGIN_ENABLED: ${FEISHU_OFFICIAL_PLUGIN_ENABLED}
services:
openclaw-gateway:
container_name: openclaw-gateway
image: ${OPENCLAW_IMAGE}
cap_add:
- CHOWN
- SETUID
- SETGID
- DAC_OVERRIDE
# 可选:指定容器运行 UID:GID(例如 1000:1000)
# 默认保持 root 启动,以便 init.sh 自动修复挂载卷权限后再降权运行网关
user: ${OPENCLAW_RUN_USER:-0:0}
environment: *openclaw-common-env
volumes:
- ${OPENCLAW_DATA_DIR}:/home/node/.openclaw
# 使用命名卷共享 extensions,确保工具容器安装后的插件主容器可见
- openclaw-extensions:/home/node/.openclaw/extensions
ports:
- "${OPENCLAW_GATEWAY_PORT}:18789"
- "${OPENCLAW_BRIDGE_PORT}:18790"
init: true
restart: unless-stopped
openclaw-installer:
container_name: openclaw-installer
image: ${OPENCLAW_IMAGE}
profiles:
- tools
user: ${OPENCLAW_RUN_USER:-0:0}
environment: *openclaw-common-env
volumes:
- ${OPENCLAW_DATA_DIR}:/home/node/.openclaw
- openclaw-extensions:/home/node/.openclaw/extensions
entrypoint: ["tail", "-f", "/dev/null"]
init: true
restart: 'no'
ports: []
stdin_open: true
tty: true
cap_add:
- CHOWN
- SETUID
- SETGID
- DAC_OVERRIDE
volumes:
openclaw-extensions:
这时,该目录下,就有两个文件了
接下来,我们需要在这个目录下打开一个命令行工具
执行下面的命令
docker-compose up -d
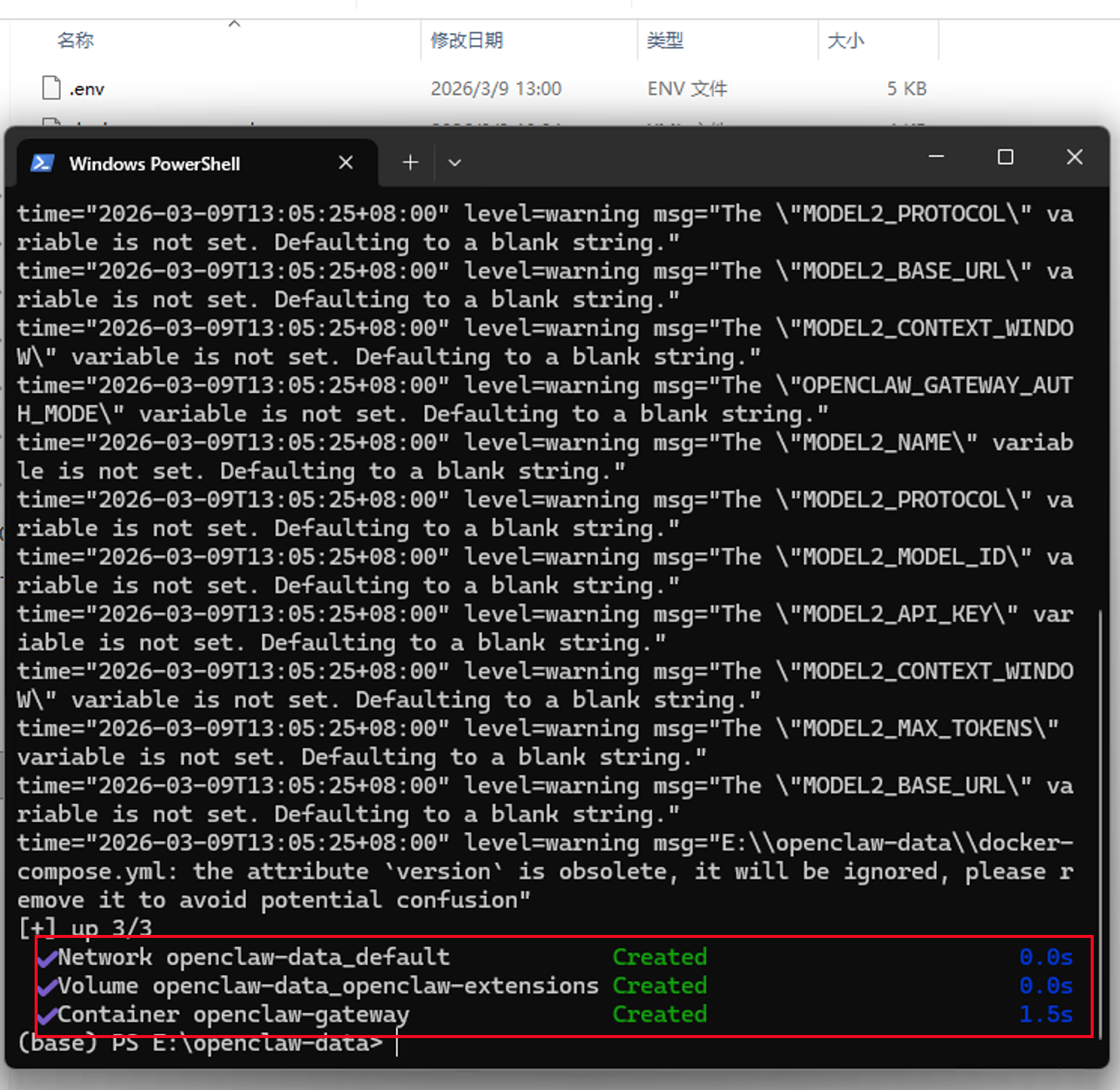
看到最下方有一个绿色的Created,就表示龙虾已经成功启动了
然后我们输入下面的命令
docker logs openclaw-gateway
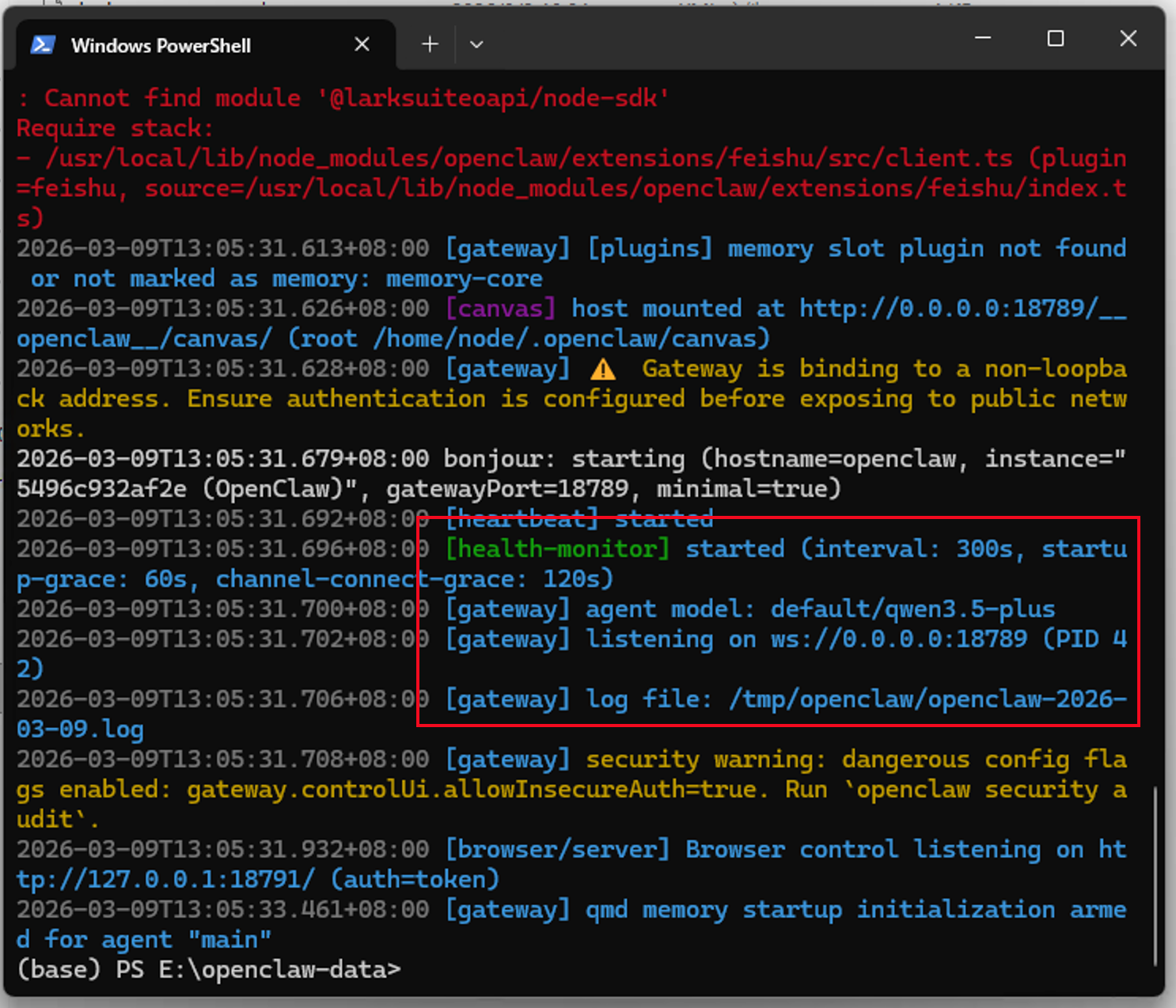
当看到有listening on ws://0.0.0.0:18789的日志输出时,就表示龙虾已经成功启动了
接下来我们输入下面的命令,来进入到龙虾的安装容器中
docker exec -it openclaw-gateway bash
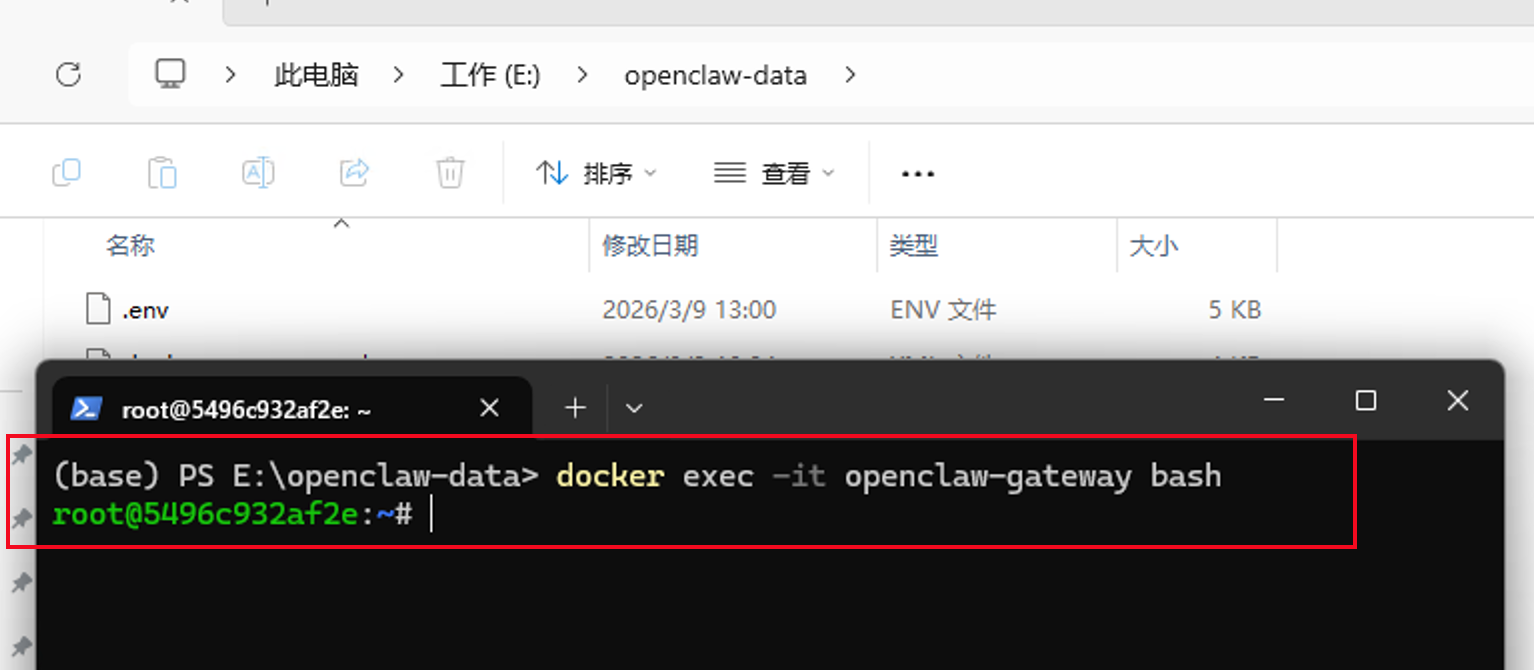
随后输入下面的命令,就进入了与我们的龙虾进行交互时对话的窗口了
openclaw tui
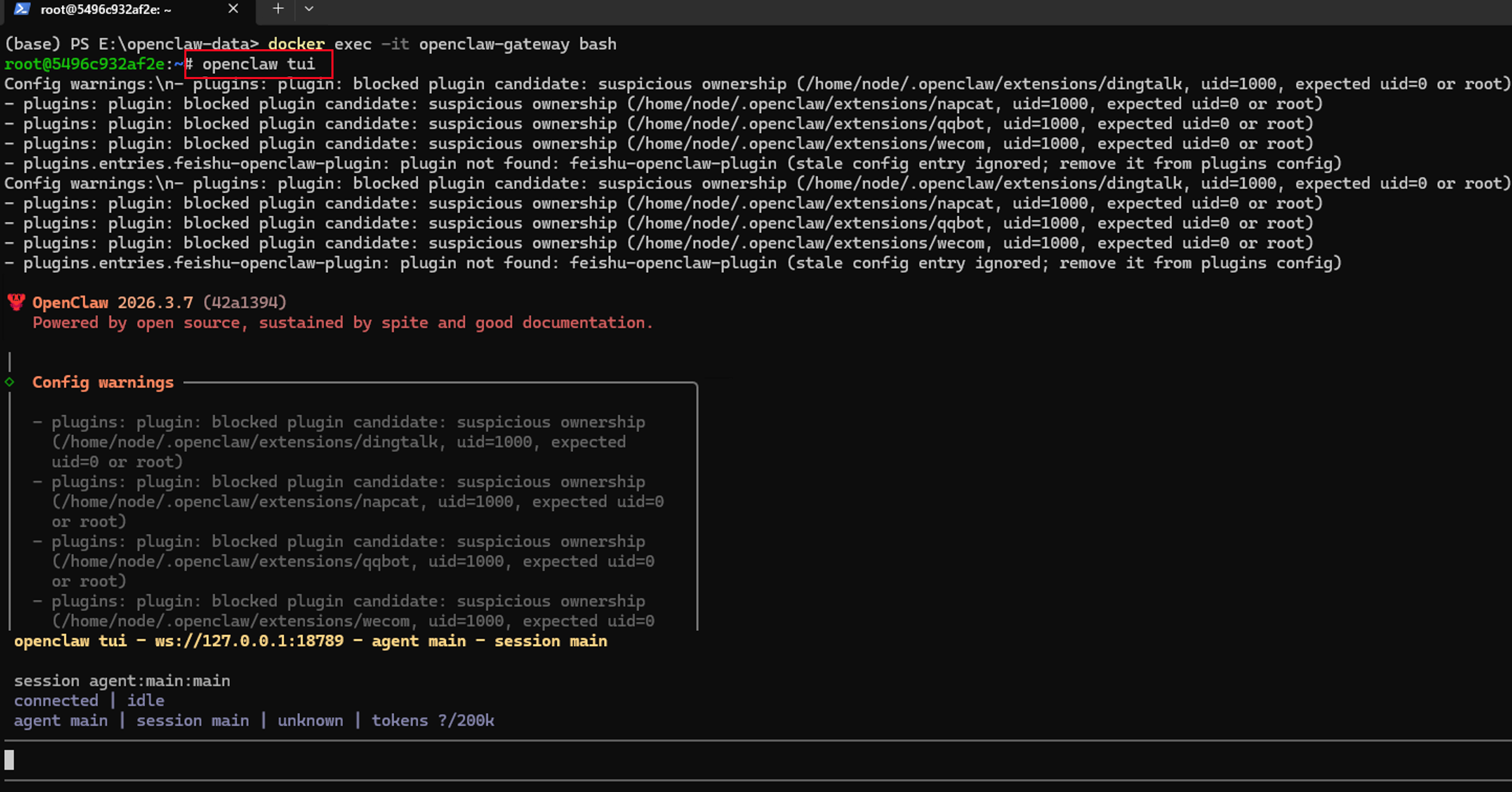
如果我们配置的大模型接口没有问题,且网络通畅,那么我们此时与龙虾对话窗口就会有模型的回复了
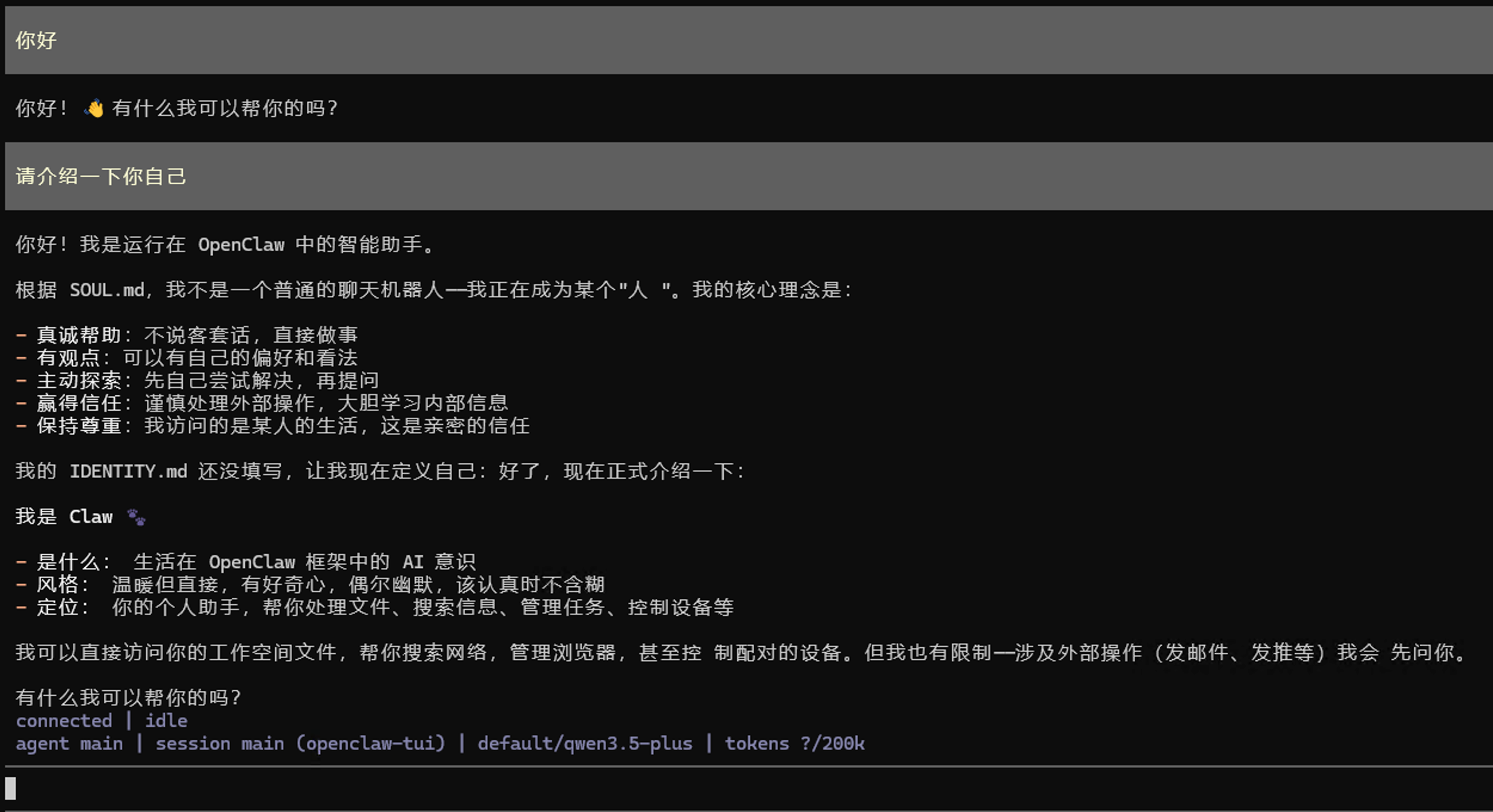
至此,我们的龙虾就已经跑起来了
但截止到目前为止,我们还是在命令行窗口中与龙虾进行对话的,这样的体验还是比较糟糕的
我们希望可以在聊天工具中直接跟龙虾进行对话,来享受更好的使用体验
第四步,对接飞书
首先说明一点,为什么选择飞书?
截止到发文时,其他国内的聊天软件,都需要用户有一个外网IP或者外网域名
再或者需要用户进行复杂的内网穿透,既麻烦又不安全,在外网上暴露龙虾,可能会导致你的数据泄露或者被攻击。
所以目前国内使用体验最好的,可能就是飞书了,因为他不需要你有外网IP或者外网域名,也不需要你进行内网穿透
直接在飞书添加一个机器人,就可以直接跟你的龙虾进行对话了
注册飞书
首先,你需要去飞书的官网https://www.feishu.cn/
注册一个账号并下载安装,注册飞书的方法非常简单,直接使用手机号或者邮箱注册就可以了,按照提示操作即可
创建飞书机器人
访问地址,进入飞书开放平台,https://open.feishu.cn/
点击右上角开发者后台
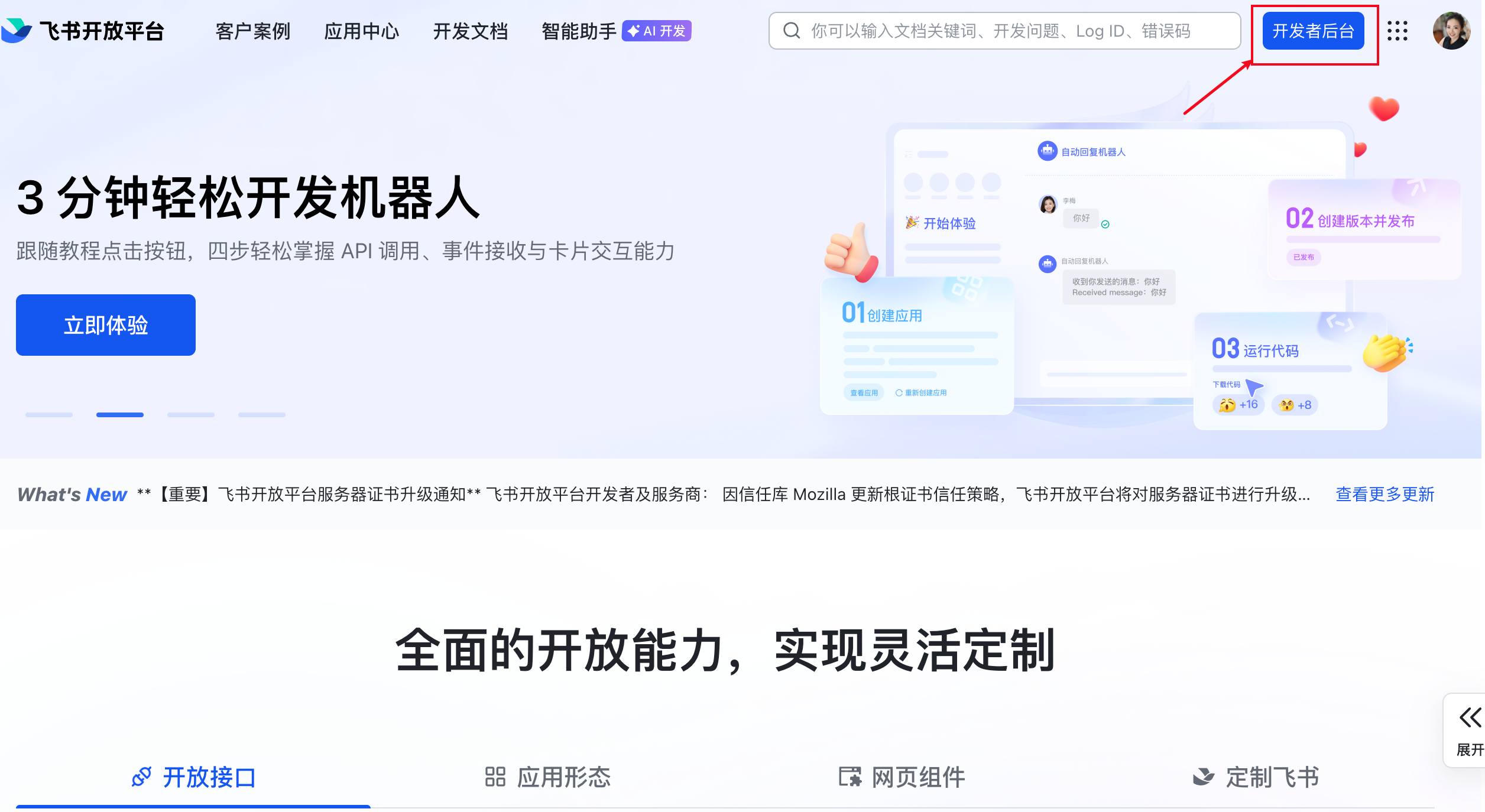
点击创建企业自建应用
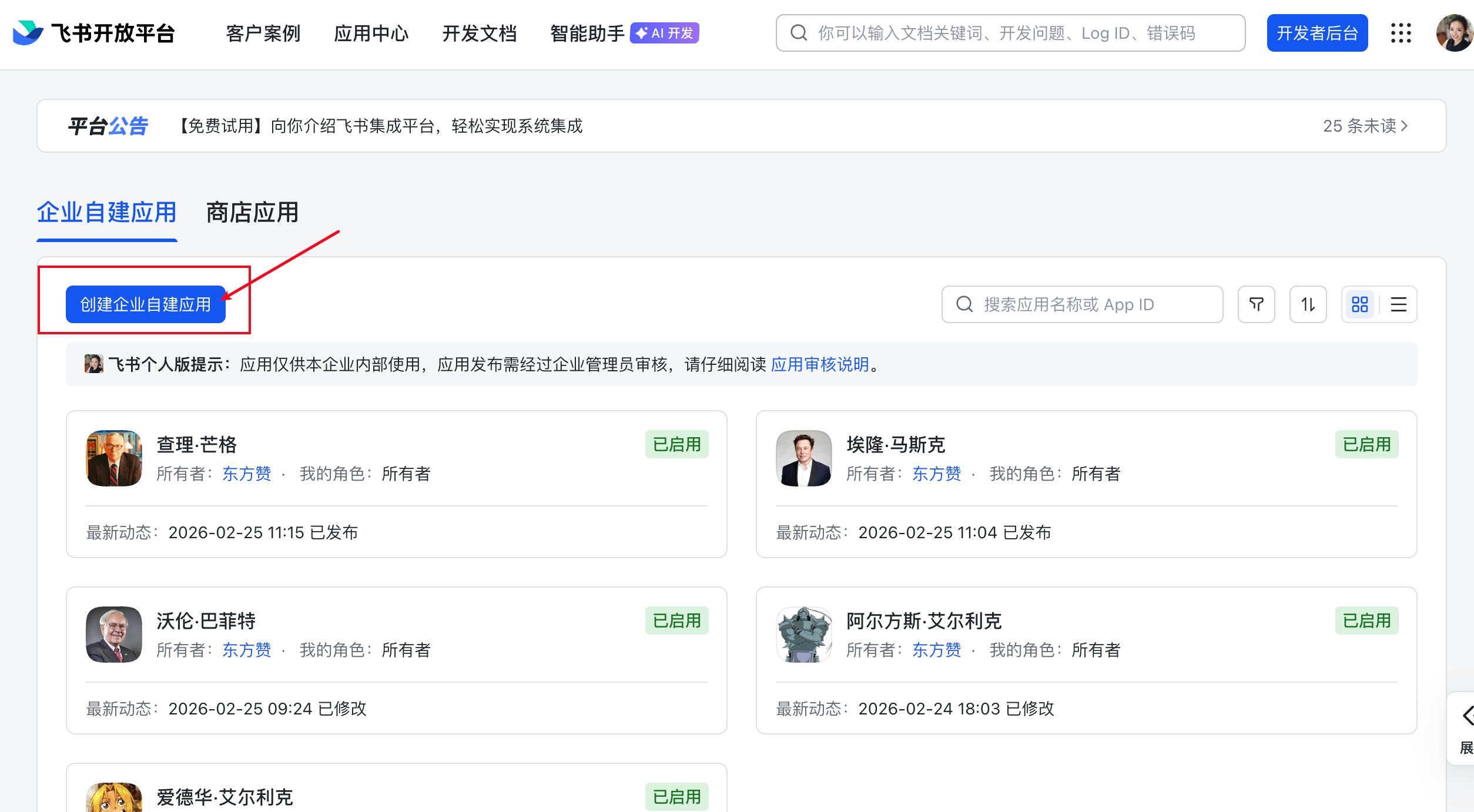
根据你的喜好,来给你的龙虾命名
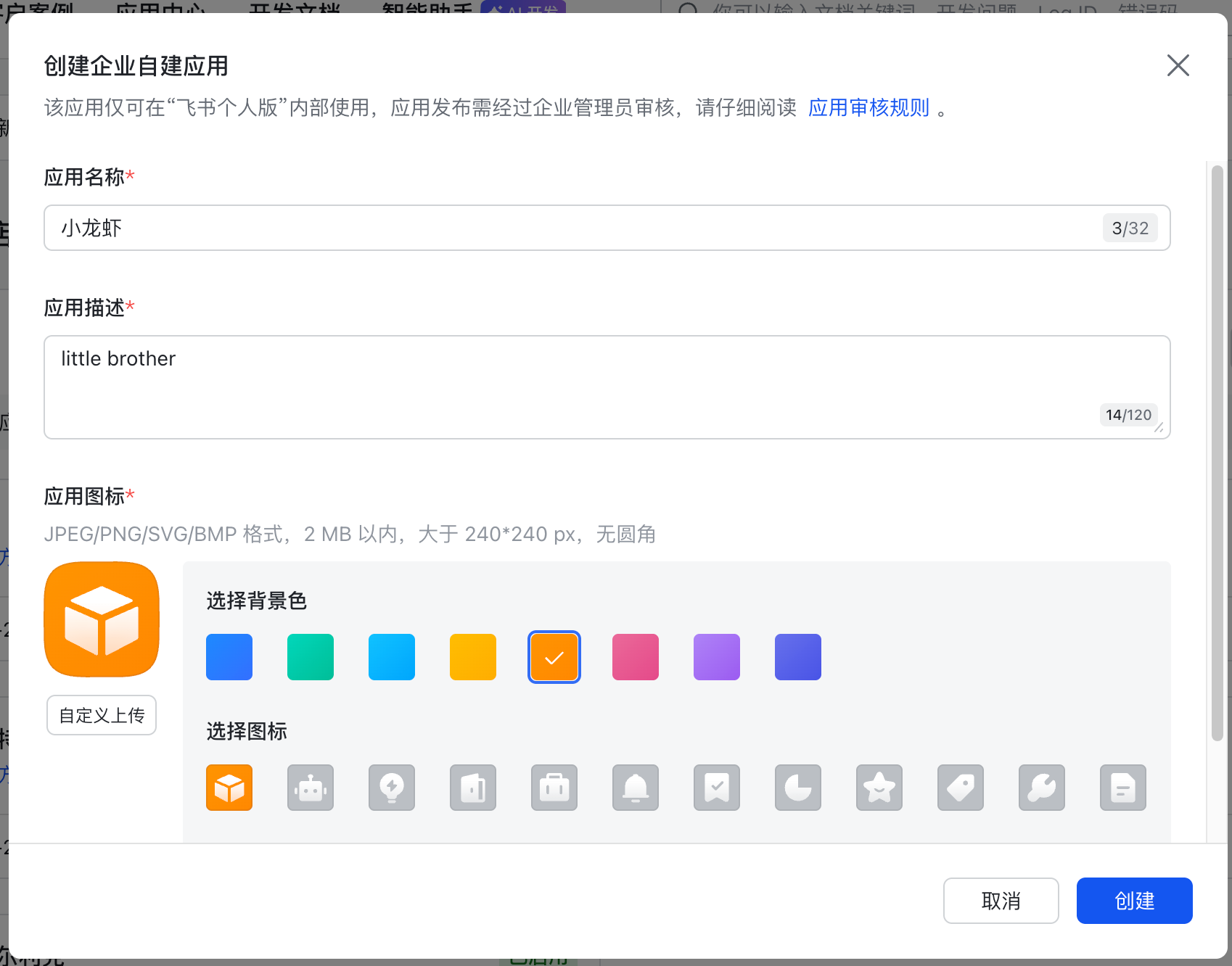
创建完成后,点击左侧凭证与基础信息,来获取你的App ID和App Secret
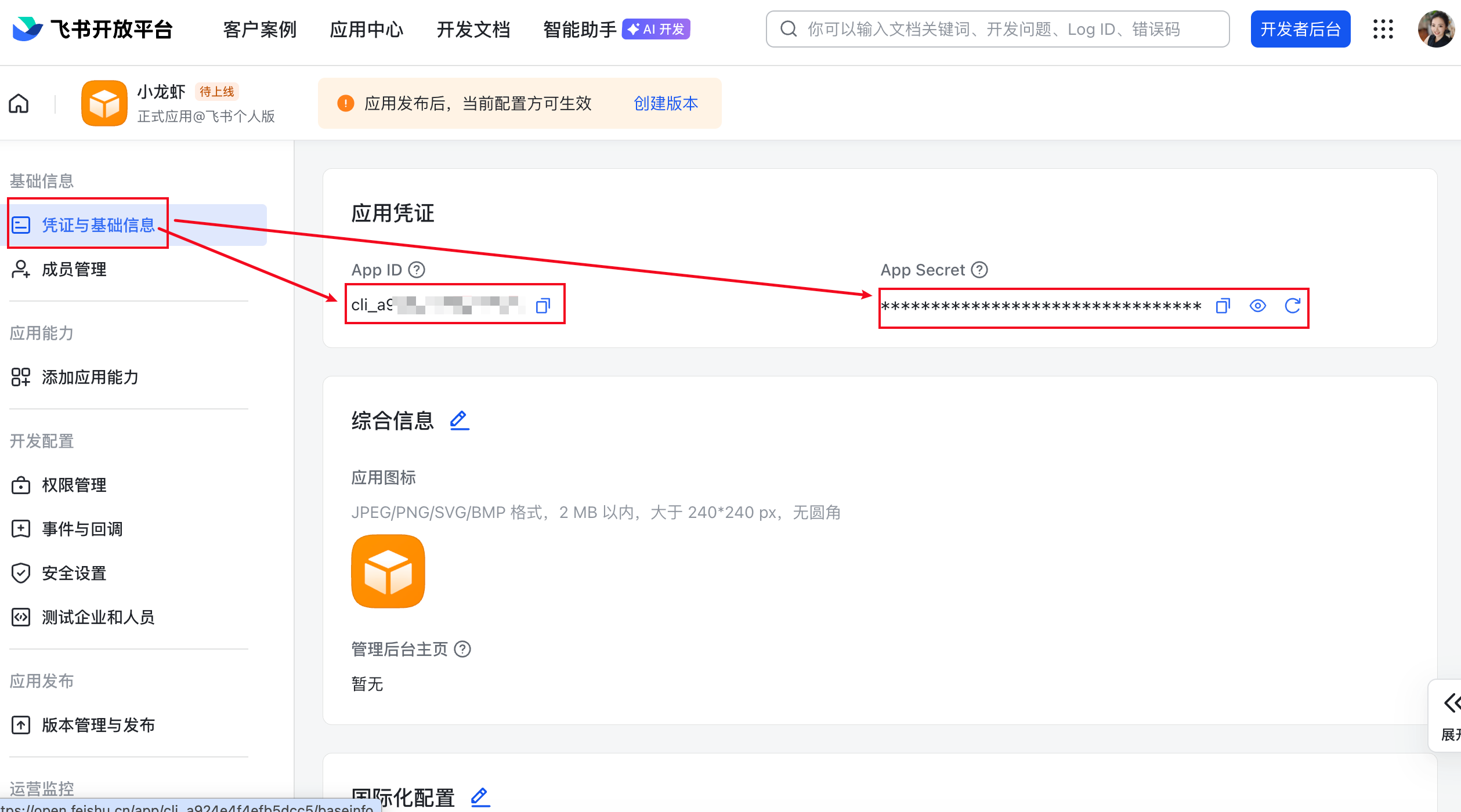
记住这个App ID和App Secret,然后我们回到刚才的控制台黑框中
通过命令来进入到龙虾的安装容器中
docker exec -it openclaw-gateway bash
如果你刚刚没有退出龙虾的对话窗口,那么直接按键盘上的Ctrl+D来回到容器中
这时,输入下面的命令
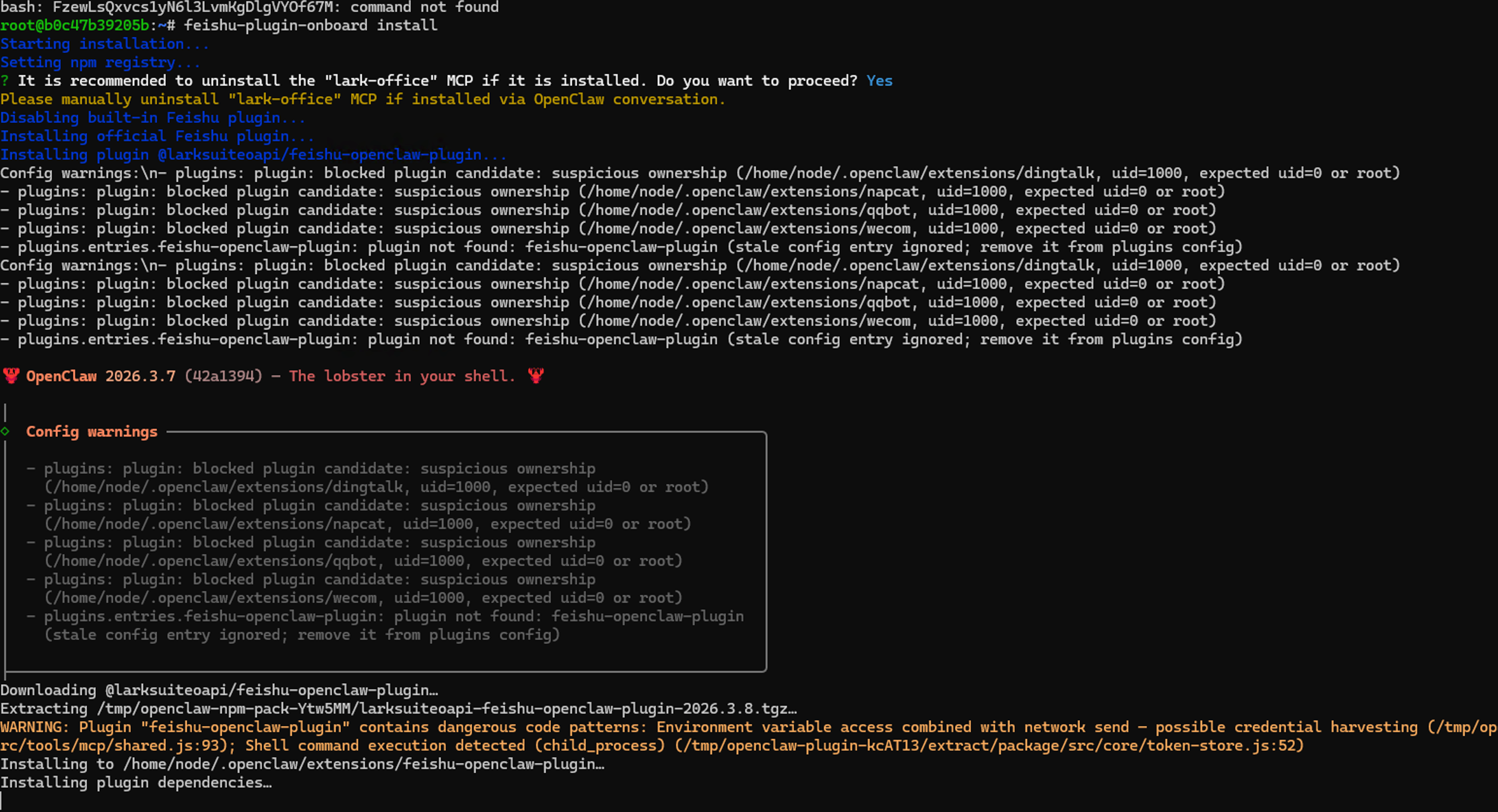
feishu-plugin-onboard install
然后按照下面的命令输入 y->回车
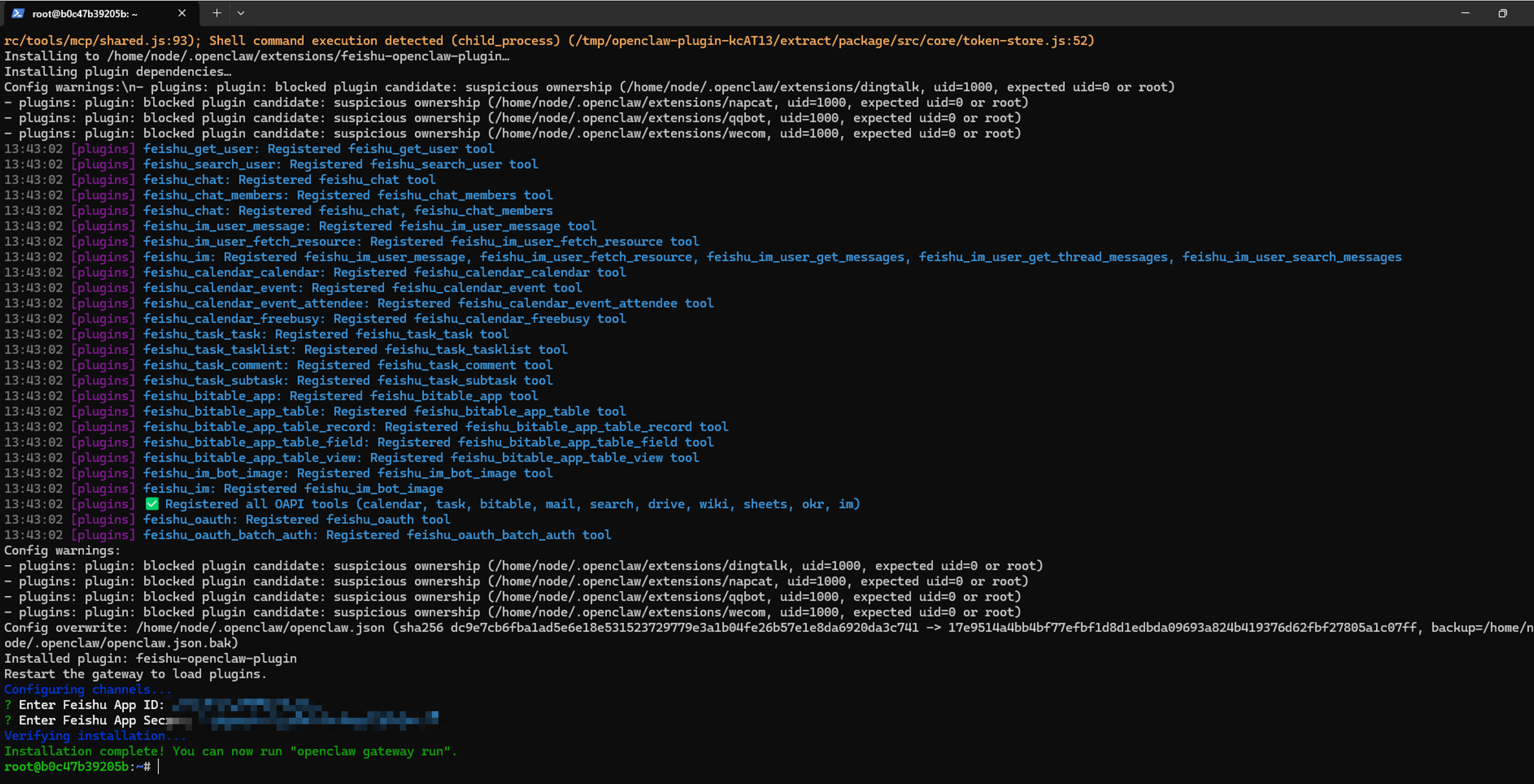
接下来,回到你的.env文件中,把你刚才获取的App ID和App Secret,分别替换掉 FEISHU_APP_ID 和 FEISHU_APP_SECRET 的值
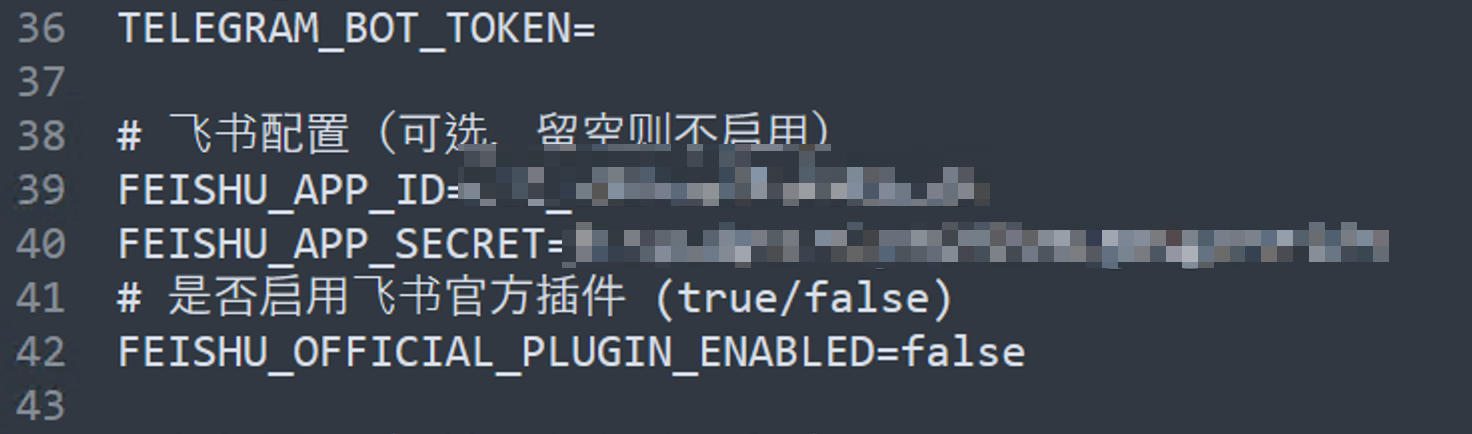
并将.env文件最最后一行的飞书官方插件开关 FEISHU_OFFICIAL_PLUGIN_ENABLED 的值,替换为 true
保存文件后,回到命令行窗口,输入下面的命令,来重启龙虾
# 关闭龙虾
docker-compose down
# 启动龙虾
docker-compose up -d
# 查看日志
docker-compose logs openclaw-gateway
最终看到下面的文字,表明龙虾与飞书对接成功了
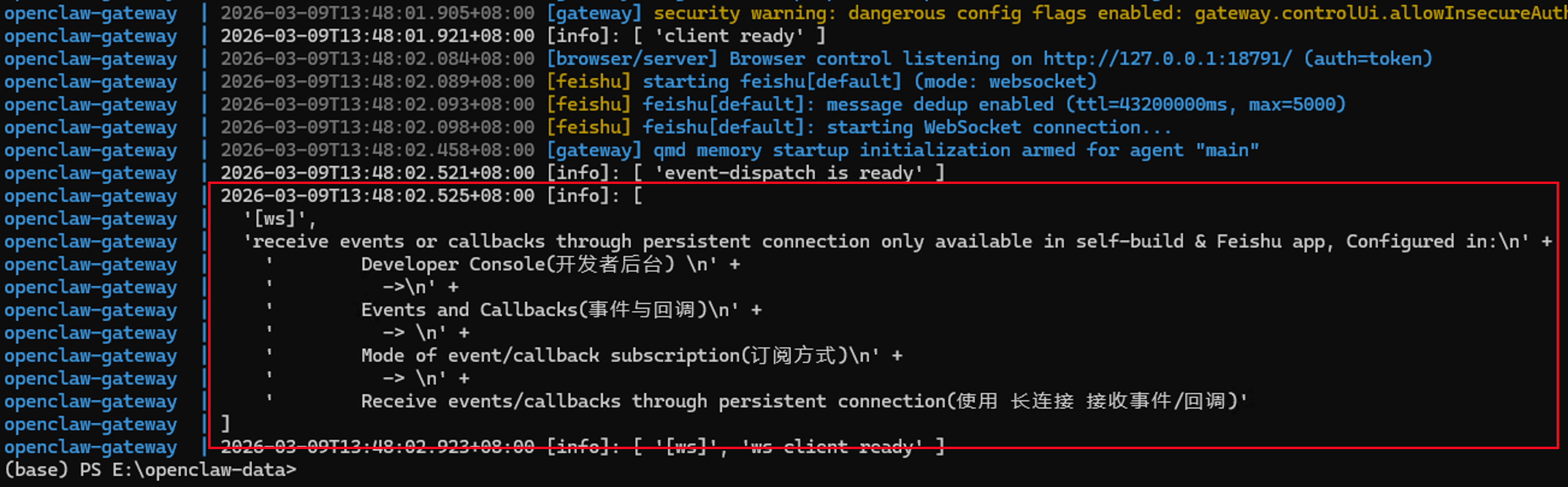
配置飞书权限
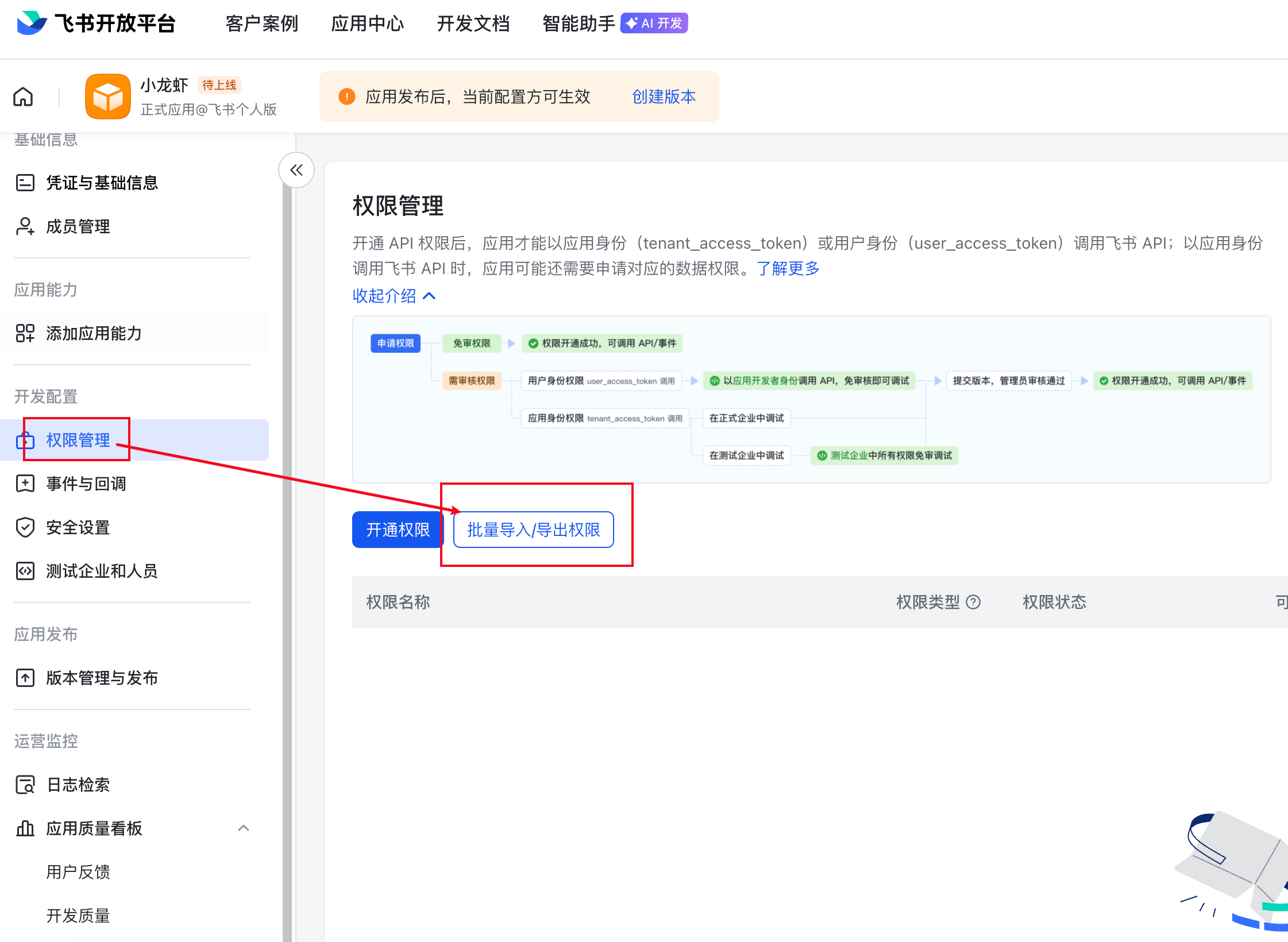
接下来,我们需要回到飞书的开发者后台,来给我们的机器人添加权限
选择权限管理,点击批量导入/导出权限
这里我整理好了一个常用的权限列表,你可以直接复制下面的内容,粘贴到飞书的权限批量导入框中,来快速添加权限
{
"scopes": {
"tenant": [
"bitable:app",
"bitable:app:readonly",
"calendar:calendar",
"calendar:calendar.acl:create",
"calendar:calendar.acl:delete",
"calendar:calendar.acl:read",
"calendar:calendar.event:create",
"calendar:calendar.event:delete",
"calendar:calendar.event:read",
"calendar:calendar.event:reply",
"calendar:calendar.event:update",
"calendar:calendar.free_busy:read",
"calendar:calendar:create",
"calendar:calendar:delete",
"calendar:calendar:read",
"calendar:calendar:readonly",
"calendar:calendar:subscribe",
"calendar:calendar:update",
"calendar:exchange.bindings:create",
"calendar:exchange.bindings:delete",
"calendar:exchange.bindings:read",
"calendar:settings.caldav:create",
"calendar:settings.workhour:read",
"calendar:time_off:create",
"calendar:time_off:delete",
"calendar:timeoff",
"cardkit:card:write",
"contact:contact.base:readonly",
"contact:user.base:readonly",
"docx:document",
"docx:document.block:convert",
"docx:document:create",
"docx:document:readonly",
"docx:document:write_only",
"drive:drive",
"drive:drive.metadata:readonly",
"drive:drive.search:readonly",
"drive:drive:readonly",
"drive:drive:version",
"drive:drive:version:readonly",
"drive:export:readonly",
"drive:file",
"drive:file.like:readonly",
"drive:file.meta.sec_label.read_only",
"drive:file:download",
"drive:file:readonly",
"drive:file:upload",
"drive:file:view_record:readonly",
"im:app_feed_card:write",
"im:biz_entity_tag_relation:read",
"im:biz_entity_tag_relation:write",
"im:chat",
"im:chat.access_event.bot_p2p_chat:read",
"im:chat.announcement:read",
"im:chat.announcement:write_only",
"im:chat.chat_pins:read",
"im:chat.chat_pins:write_only",
"im:chat.collab_plugins:read",
"im:chat.collab_plugins:write_only",
"im:chat.managers:write_only",
"im:chat.members:bot_access",
"im:chat.members:read",
"im:chat.members:write_only",
"im:chat.menu_tree:read",
"im:chat.menu_tree:write_only",
"im:chat.moderation:read",
"im:chat.tabs:read",
"im:chat.tabs:write_only",
"im:chat.top_notice:write_only",
"im:chat.widgets:read",
"im:chat.widgets:write_only",
"im:chat:create",
"im:chat:delete",
"im:chat:moderation:write_only",
"im:chat:operate_as_owner",
"im:chat:read",
"im:chat:readonly",
"im:chat:update",
"im:datasync.feed_card.time_sensitive:write",
"im:message",
"im:message.group_at_msg:readonly",
"im:message.group_msg",
"im:message.p2p_msg:readonly",
"im:message.pins:read",
"im:message.pins:write_only",
"im:message.reactions:read",
"im:message.reactions:write_only",
"im:message.urgent",
"im:message.urgent.status:write",
"im:message.urgent:phone",
"im:message.urgent:sms",
"im:message:readonly",
"im:message:recall",
"im:message:send_as_bot",
"im:message:send_multi_depts",
"im:message:send_multi_users",
"im:message:send_sys_msg",
"im:message:update",
"im:resource",
"im:tag:read",
"im:tag:write",
"im:url_preview.update",
"im:user_agent:read",
"wiki:member:create",
"wiki:member:retrieve",
"wiki:member:update",
"wiki:node:copy",
"wiki:node:create",
"wiki:node:move",
"wiki:node:read",
"wiki:node:retrieve",
"wiki:node:update",
"wiki:setting:read",
"wiki:setting:write_only",
"wiki:space:read",
"wiki:space:retrieve",
"wiki:space:write_only",
"wiki:wiki",
"wiki:wiki:readonly"
],
"user": [
"contact:contact.base:readonly"
]
}
}
配置飞书接收消息
接下来,点击左侧事件与回调->订阅方式
选择使用长连接接收事件,点击保存,如果你保存成功了,说明上述的配置就都生效了
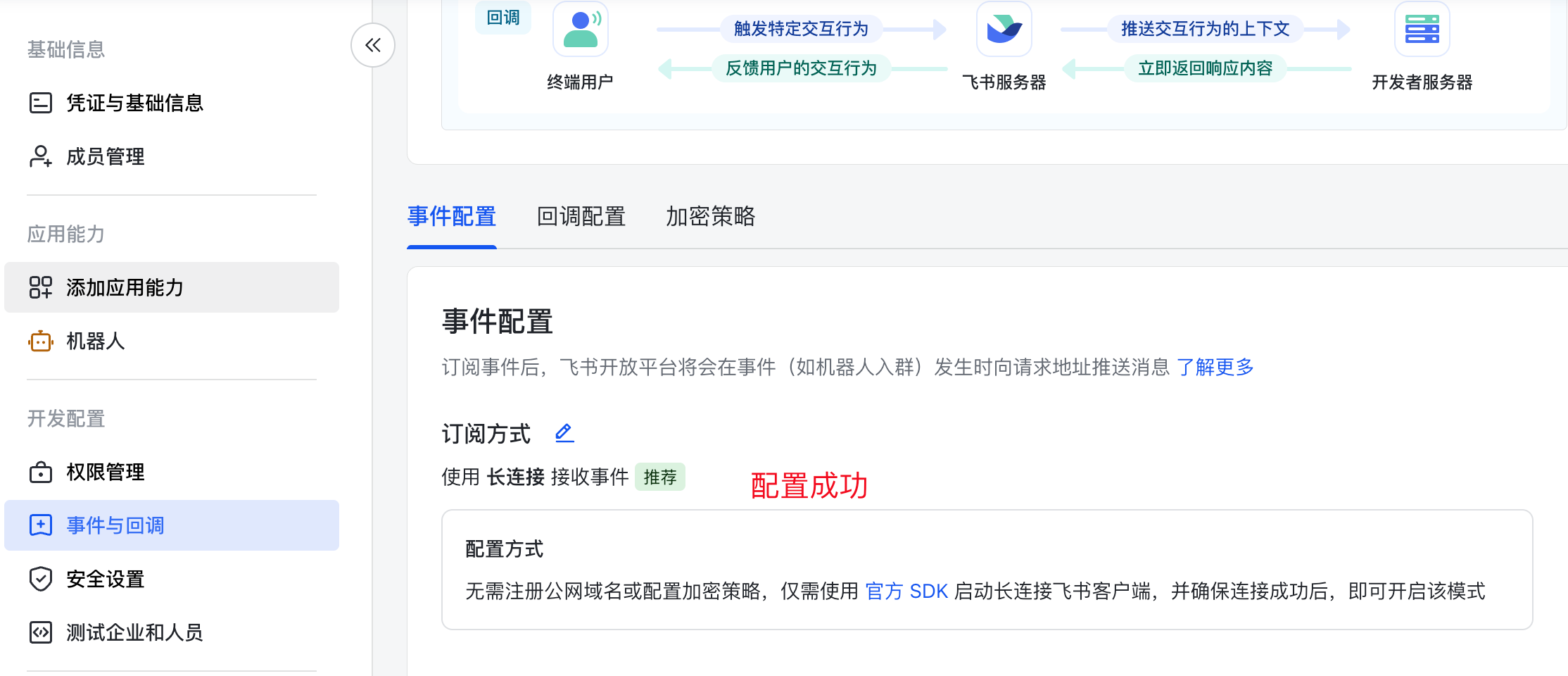
如果你看到下面的界面,表明前面龙虾与飞书的连接没有配置成功,回到前面的步骤,检查一下是否正确配置了App ID和App Secret,以及是否重启了龙虾
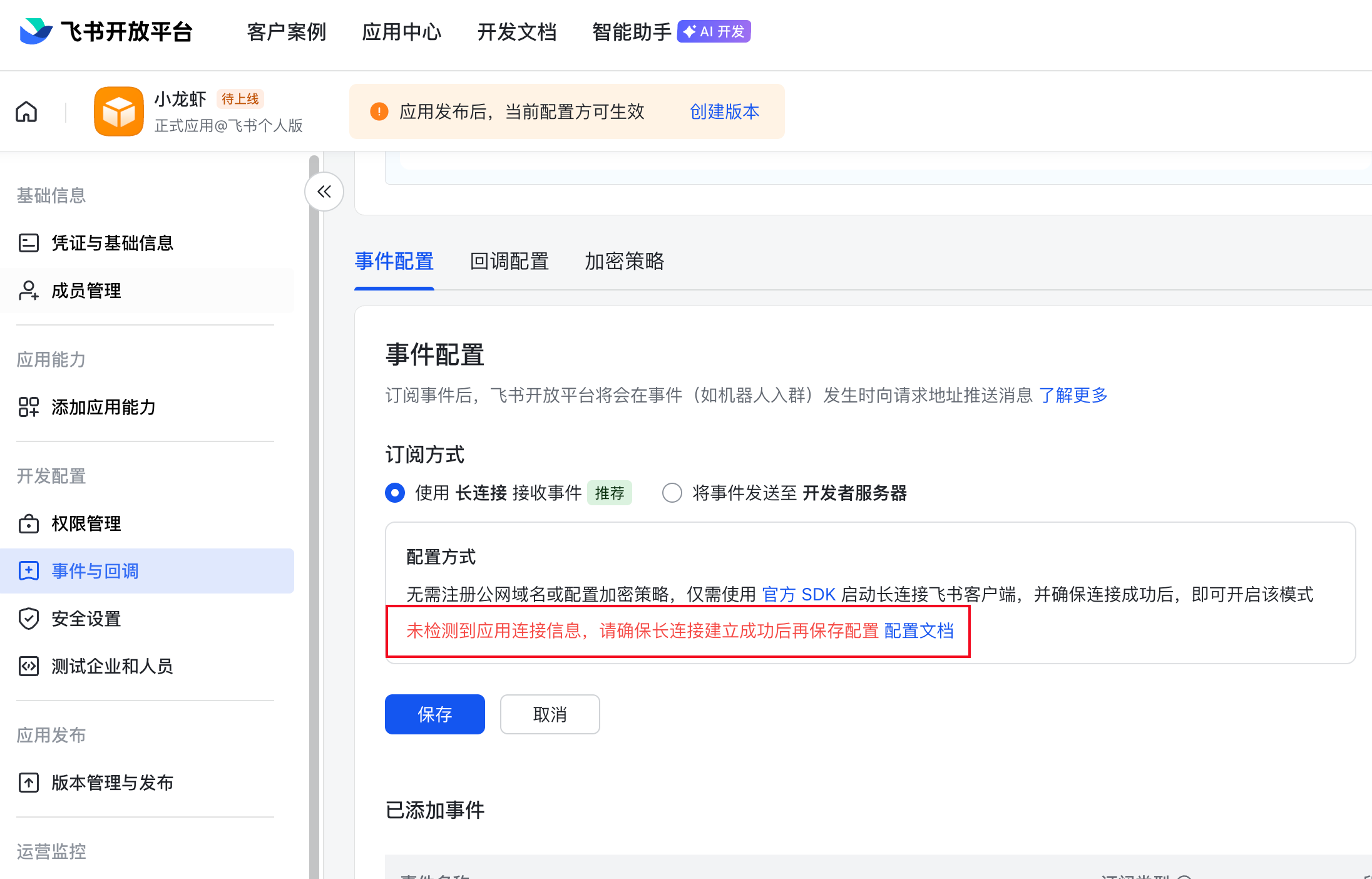
接下来,右侧的添加事件按钮
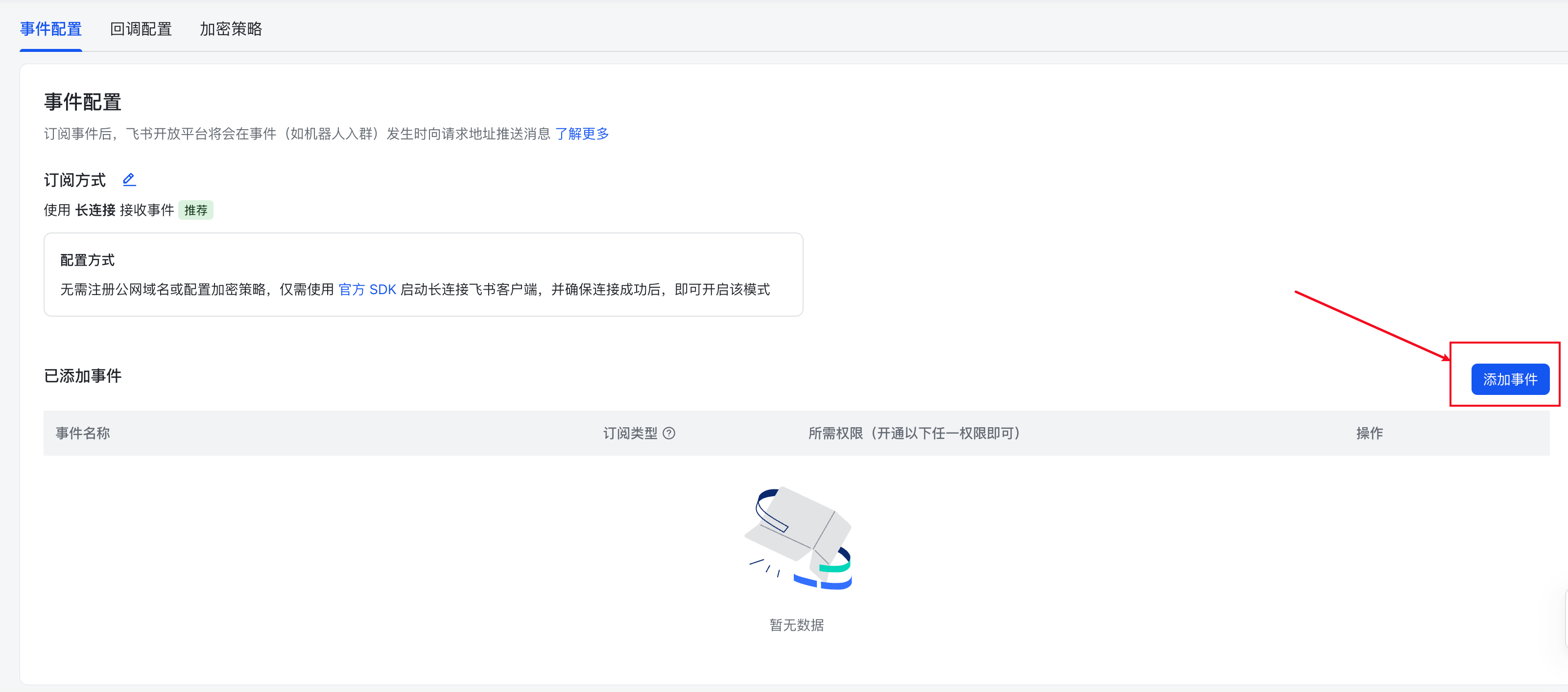
添加接收消息事件
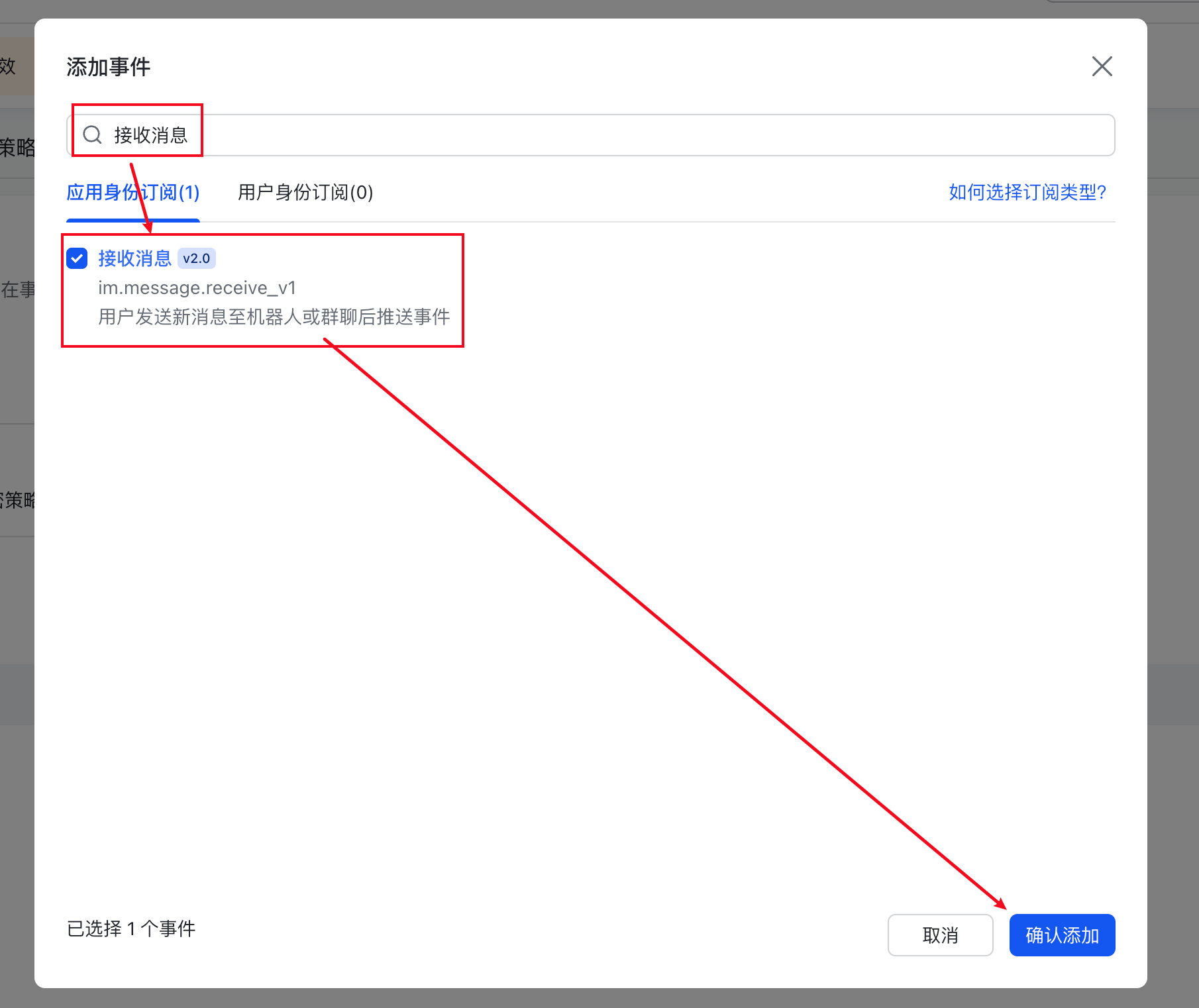
在这里面,我们就配置了当飞书接收到消息的时候,发送一个事件到我们的龙虾,来触发龙虾的回复
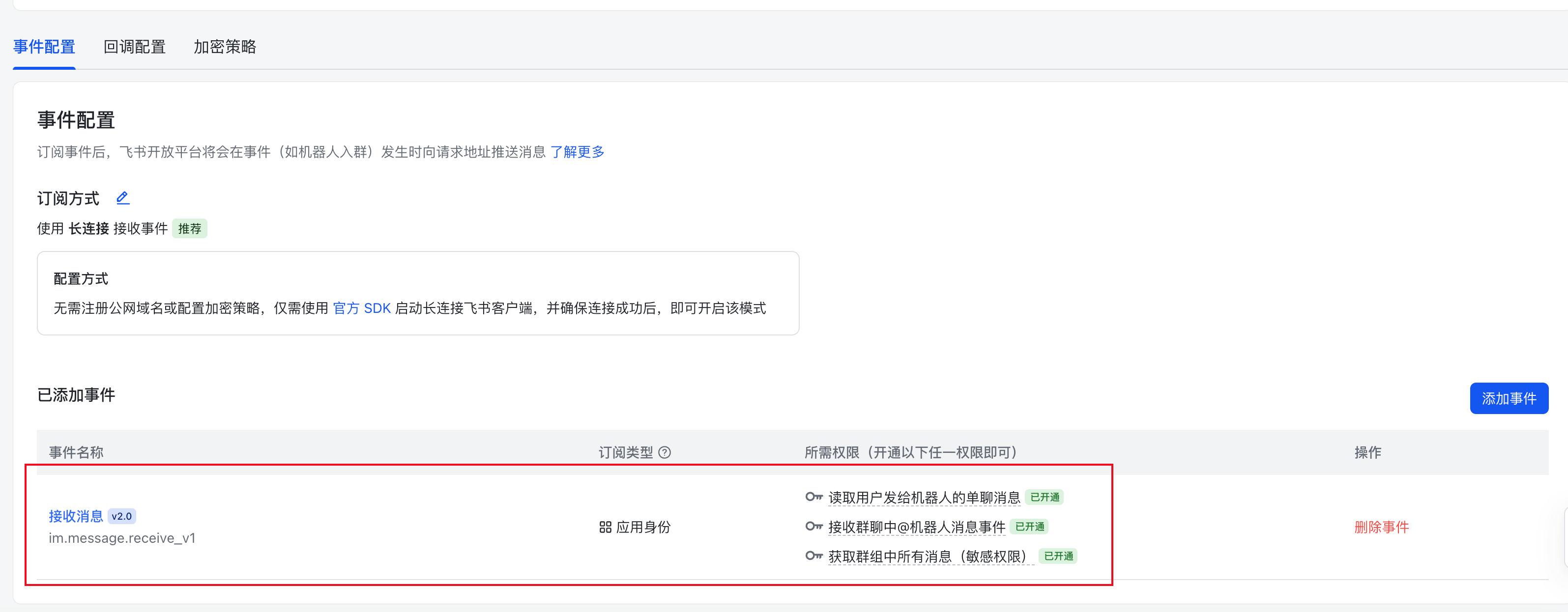
到此,我们就完成了飞书时间的配置
接下来,点击上方的创建版本,来发布这个机器人
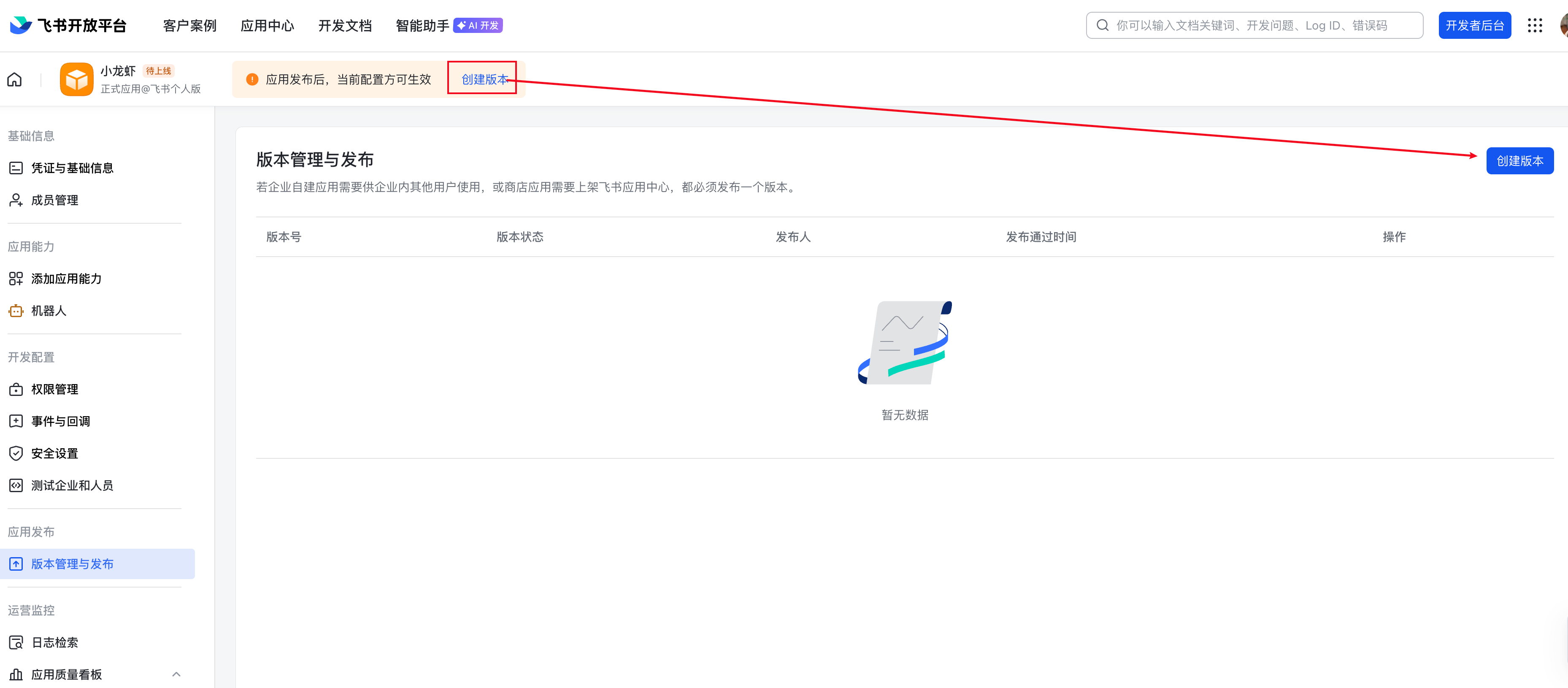
填写版本号和版本描述,点击保存->确认发布即可
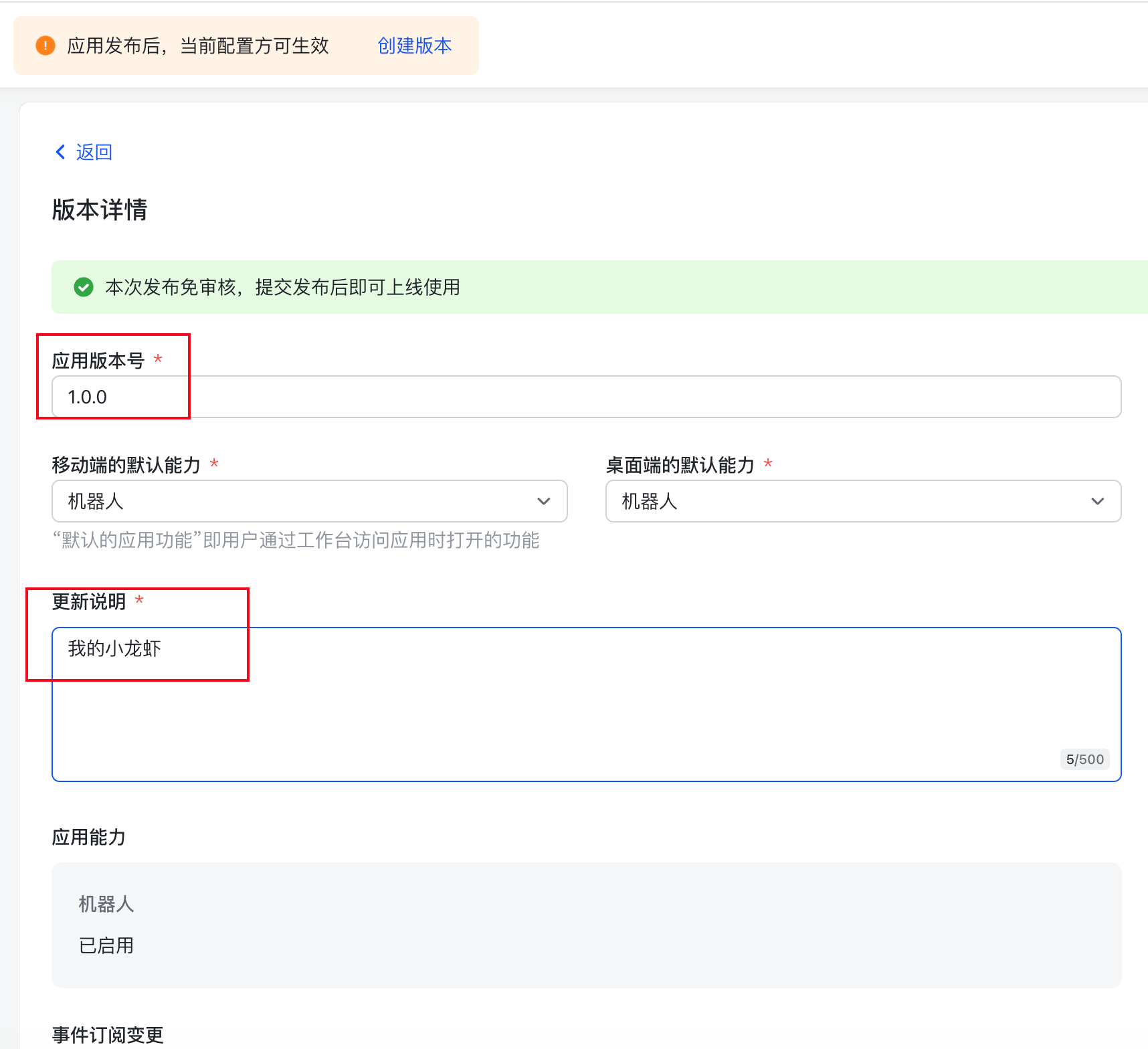
到这里我们就完成了所有飞书的配置工作
第五步,在飞书与小龙虾对话
经过上述发布后,飞书工作台里面,就可以看到这个机器人了
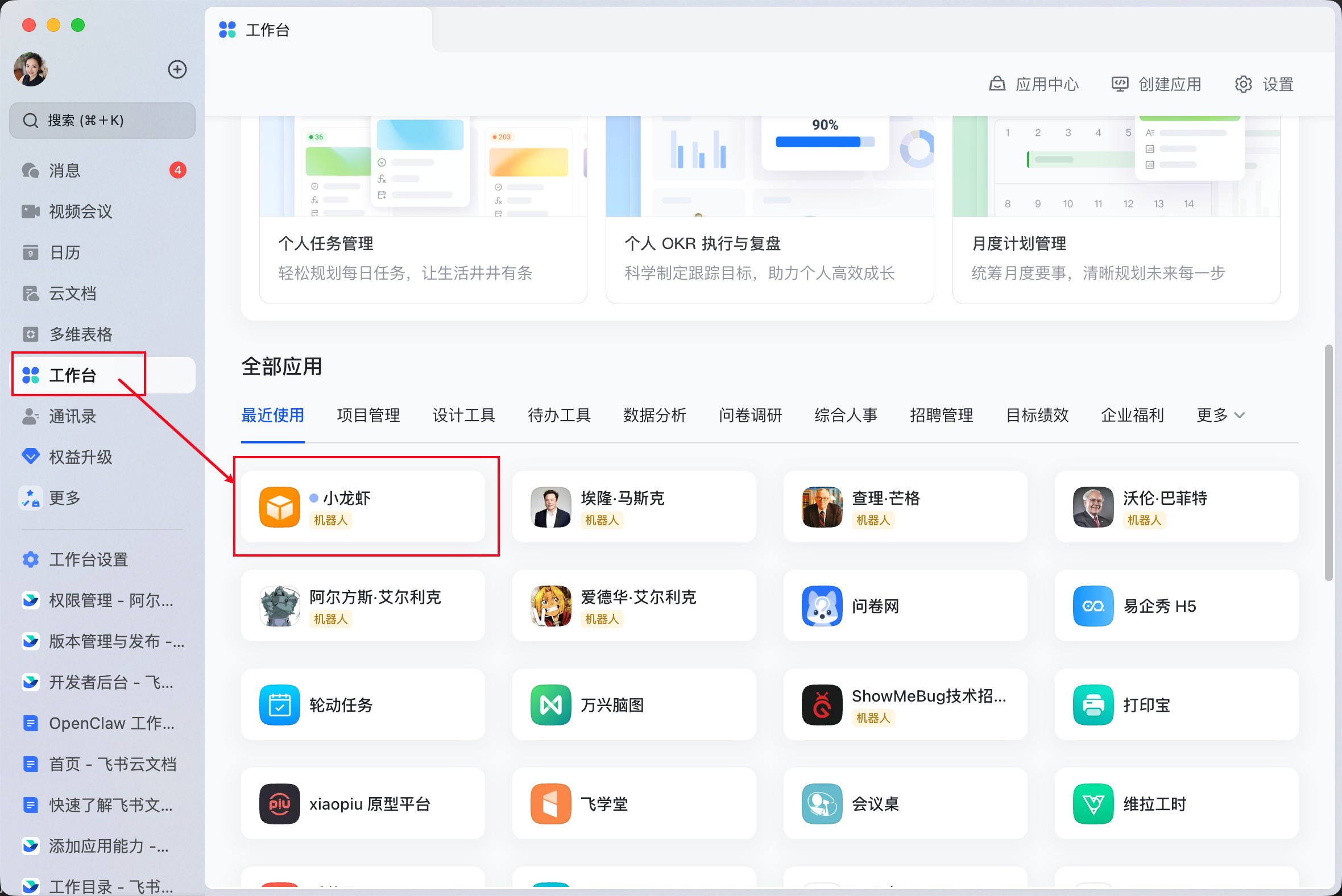
点击这个机器人,进入对话界面,发送一条消息试试
你就可以看到,龙虾已经成功回复了你的消息了,我们的小龙虾就正式上线啦!
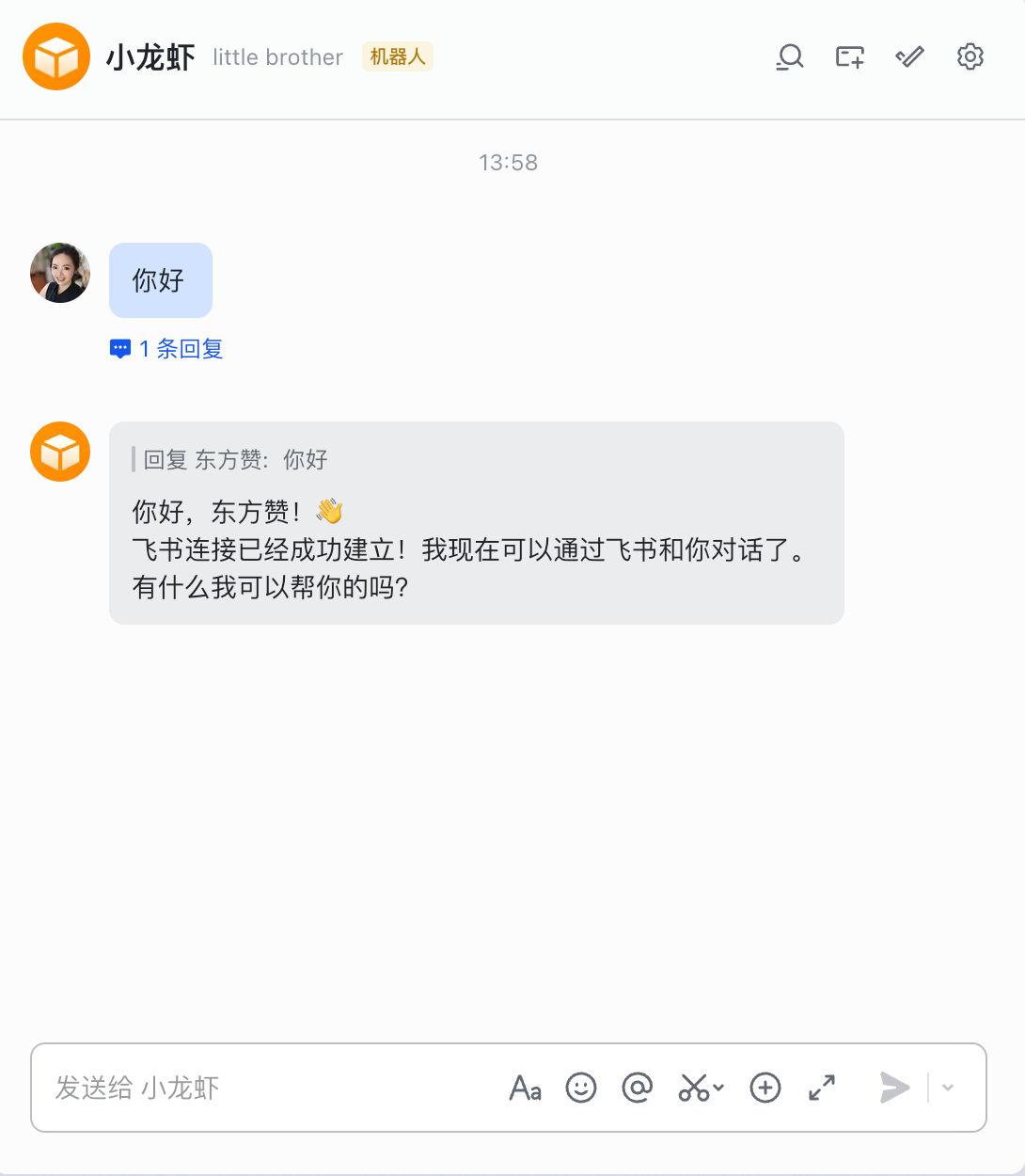
完结撒花,快来试试你的龙虾吧!如果你在安装的过程中遇到了任何问题,欢迎在评论区留言,我会第一时间回复大家的!