本地部署大模型接入 Claude Code 全攻略:轻松实现不限量 Vibe Coding

2026 年,AI 编程已经成为主流趋势,而 Anthropic 的 Claude Code 凭借其强大的代码理解和生成能力,迅速赢得了开发者的青睐。🎉
Anthropic 系列模型主要以云端服务形式提供,受限于网络和昂贵的价格,很多开发者希望能在本地部署类似能力的大模型
国内最近开源的 Kimi-K2.5 / GLM-4.7 / MiniMax-M2.1 等模型,具备强大的编程能力,可以说在一定程度上替代 Anthropic 系列模型
可以在享受不限速的本地推理体验的同时摆脱网络和费用的束缚,并保证数据的隐私安全
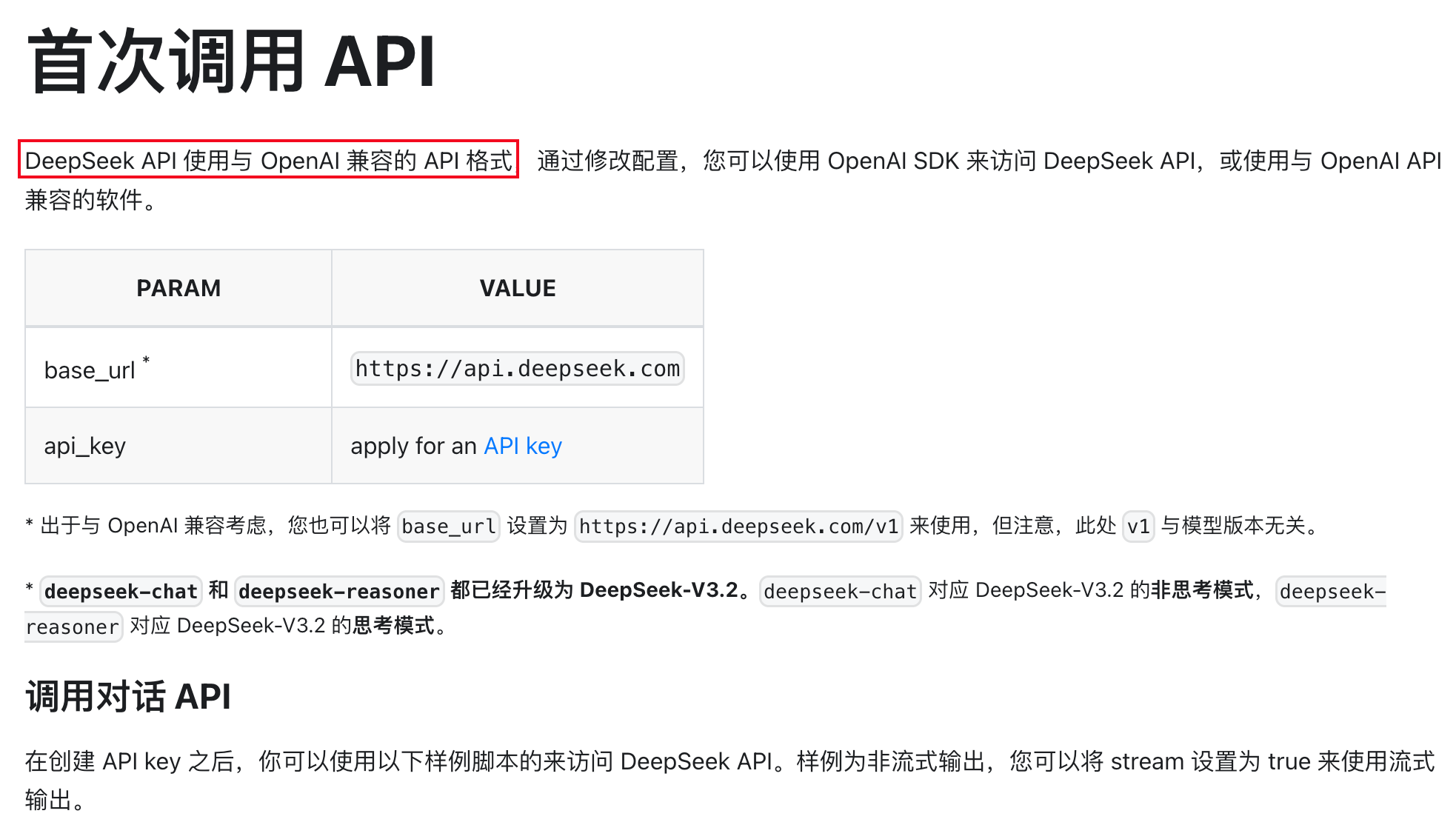
但是目前本地部署的开源方案中,大多数模型部署后都只支持 OpenAI 兼容格式的接口
无法直接兼容 Anthropic 的调用格式,这就给想要无缝切换到本地模型的开发者�带来了不便
本篇文章,我们将分享如何利用本地部署大模型,助你轻松实现不限量的 Vibe Coding 体验!
接口之争
在介绍如何接入之前,我们可以先了解一下目前主流的 AI 接口格式,具体都有哪些区别
对这部分内容已经了解的朋友可以直接跳过到后面如何使用转换器的章节。
目前主流的 AI 接口主要有三种
1. OpenAI /chat/completions 接口
这个接口相信大家都比较熟悉,在 2022 年末,ChatGPT 发布时,OpenAI 推出了这个接口,迅速成为行业标准
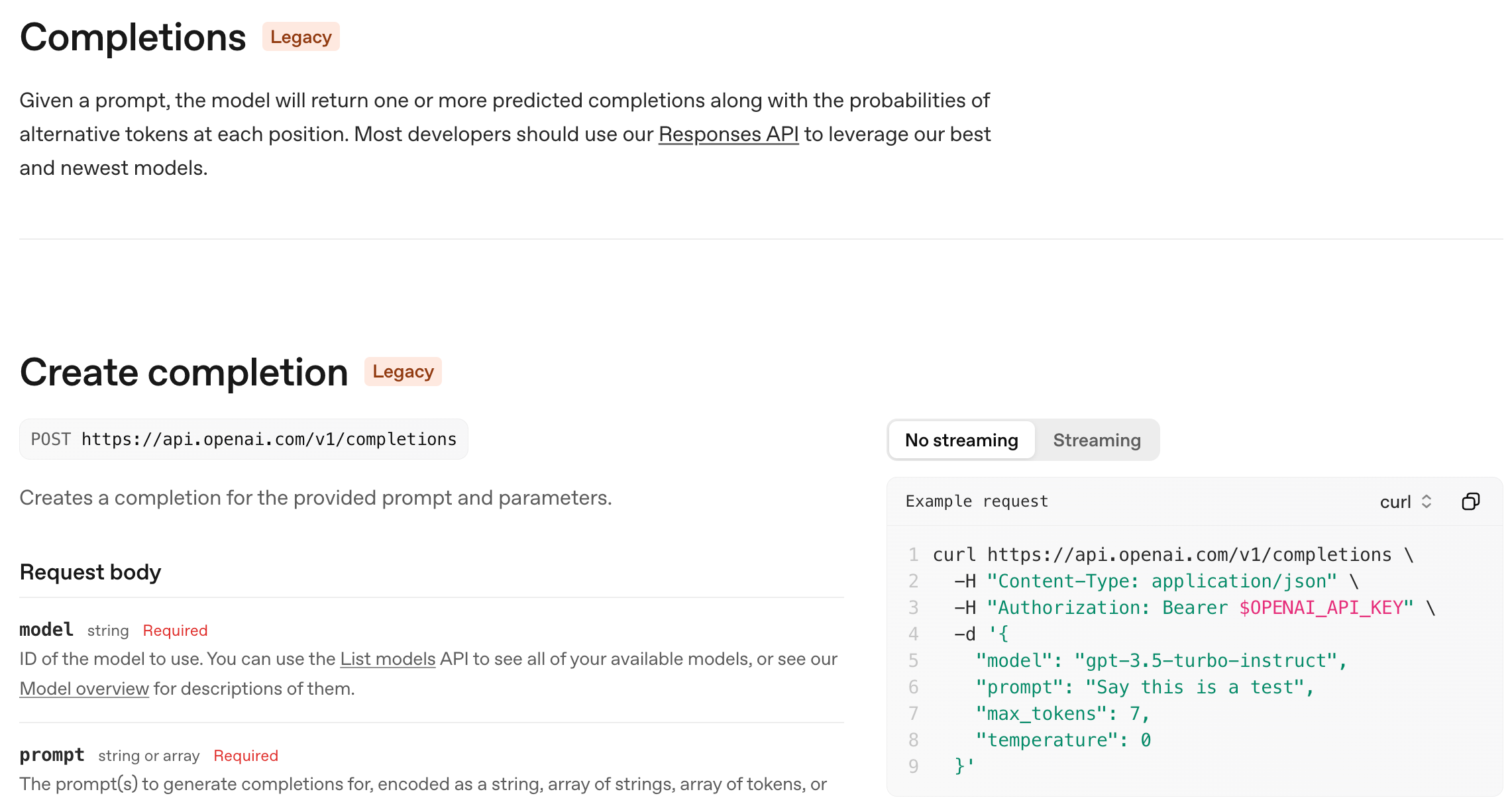
几乎所有的模型厂商都兼容这个接口,这也是我们最常用的接口。
这个接口顾名思义,本质是为了对话文本生成快速做出来的接口,且非常简单易用
它的核心假设是:
- 一次请求 = 一次文本回复
- 你自己管理上下文
- 工具调用是后来硬塞进去的(function calling)
这在 2023 年是非常合理的设计,因为当时大多数模型都只是对话工具
2. OpenAI /responses 接口
到了 2025 年,随着大模型能力的发展,Agent 智能体、多模态、工具调用已经越来越重要
原来的/chat/completions历史包袱太重,已经无法很好地支持这些新兴的复杂交互场景
OpenAI 在 2025 年 3 月份发布了一个新的接口 /responses,这个接口本质上是为了更好地支持复杂交互设计的
在这个全新的接口中,增加了原生的 Agent 能力:
- 内置 tool use:file_search、code_interpreter、image_generation、web_search、MCP 等
- 一次 responses 调用里可以发生多次
模型-工具-模型循环
增加了 原生的状态(stateful) 支持,保持会话状态,让每次推理不再失忆
与此同时,多模态也不再是给 chat 接口加个字段,而是:
- text / image / audio / file 都是一等公民
- 输出也是多 item(text + tool_call + structured output)
这对真正做产品级应用很重要,OpenAI 也在积极的推动这个接口的生态建设
比如现在的 OpenAI 推出的编程工具 Codex 就是基于这个接口设计的

3. Anthropic /messages 接口
Anthropic 的 /messages 接口,在原理上其实与 OpenAI 的 /chat/completions 接口更为接近
他们在文本对话的基础上��,增加了多模态、工具调用的能力,并没有额外基于 Agent 去设计一套全新的接口
但有趣的是,Anthropic 是一家工程能力非常强的公司,他们在过去一年中,专注于 Agent 的落地
在 AI 编程这个领域,打造了一个非常强大的编程 Agent 工具 Claude Code
使得基于这一套 /messages 接口,利用工具调用、MCP、Agent Skills 等能力,能够实现非常高效的交互能力
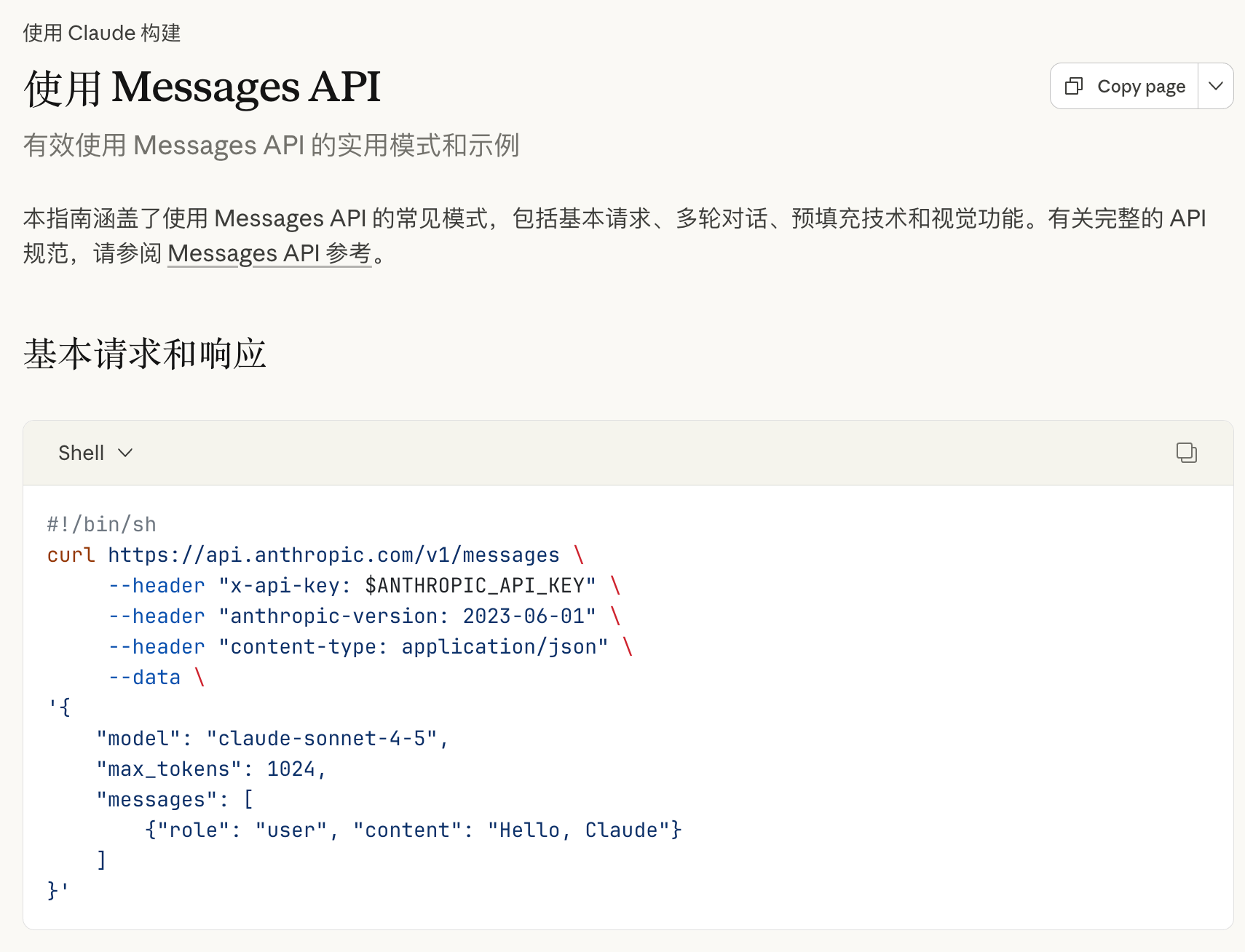
随着 Claude Code 越来越流行,越来越多的开发者希望能够直接调用兼容 Anthropic 的 /messages 接口,来利用 Claude Code 的强大能力
很多国内厂家也开始支持 Anthropic 的接口规范
虽然 OpenAI 的 /responses 接口在设计上看起来更超前,更优秀
但 Anthropic 的 /messages 接口,凭借其强大的生态和落地能力,似乎已经成了 Agent 开发的事实标准
本地部署大模型接入 Claude Code 全攻略
现在,回到我们的主题,如何将本地部署的大模型,接入到 Claude Code 体系中?
当前我们本地部署大模型,通常会采用以下三种推理引擎来运行大模型
- Ollama
- vLLM
- SGLang
绝大多数非自研模型的 AI 接口提供商,大体上也是基于以上的推理引擎进行修改而来的
1. Ollama
Ollama 作为目前桌面端使用最多的推理引擎,一开始就已经支持了 OpenAI 的 /chat/completions 接口
2026 年初,Ollama 也发布了对 Anthropic /messages 接口的支持
所以,如果你使用 Ollama 来部署模型,那么直接调用本地的 Ollama 服务即可
你需要升级到 Ollama 最新版本,才能支持 Anthropic 接口,至少>=
v0.15.0
2. vLLM
vLLM 作为目前最流行的云端推理引擎,支持了最多类型的 API
上述我们提到的三种主流接口,vLLM 都已经支持
如果你使用 vLLM 来部署模型,在启动模型成功时,看到 vLLM 支持的 API

3. SGLang
SGLang 作为目前另外一款跟 vLLM 齐名的推理引擎,目前只支持 OpenAI 的 /chat/completions 接口
在当前的版本中,还没有对 Anthropic 的 /messages 接口提供支持
但在今年的 Roadmap 中,SGLang 团队已经明确表示会支持 Anthropic 接口
只是具体的发布时间还未确定,所以如果你使用 SGLang 来部署模型,目前还无法直接支持 Anthropic 接口调用
简单总结
我们总结一下,如果你使用 Ollama 或 vLLM 来部署模型
那么恭喜你,你可以直接调用本地的 Anthropic 接口来实现接入 Claude Code
如果你使用SGLang来部署模型,那就比较惨了,目前就只有干瞪眼了
那么有的同学可能会问了
我不知道我们公司是用啥部署的,只有一个/chat/completions接口
或者你像我一样,希望可以享受 SGLang 的高性能,那该怎么办呢?
Claude Code Router

github 地址: https://github.com/musistudio/claude-code-router
顾名思义,这是一款可以将各种类型的 AI 接口,转换成 Anthropic /messages 接口的转换器
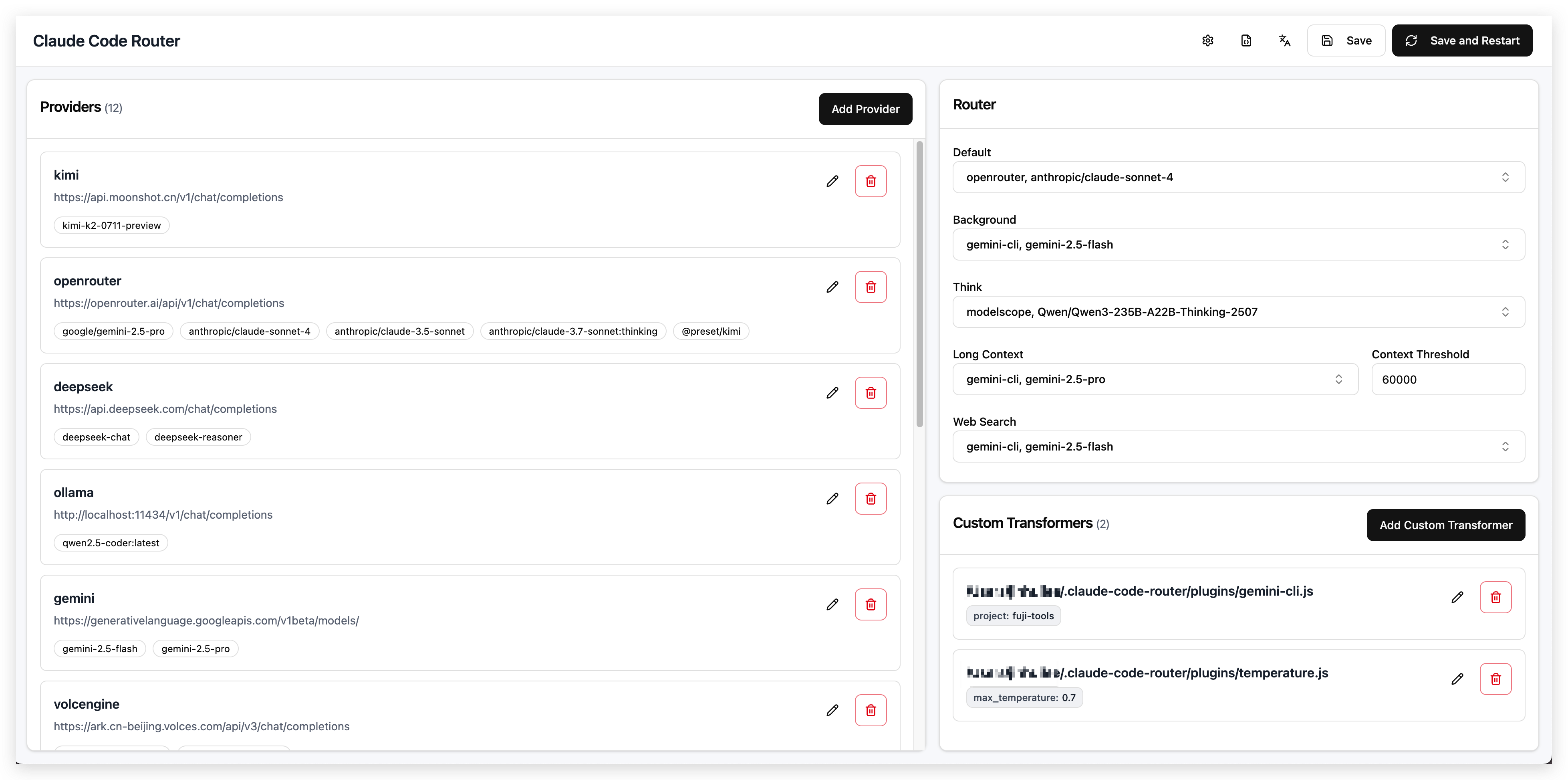
同时可以对你所有的模型进行路由
目前 github 上已经积累了 25k+ stars,受到了社区的广泛关注
你可以进入他的 github 仓库,查看详细的使用说明,只需要几步配置就可以完成部署
local-openai2anthropic
Claude Code Router 是一��款非常好用的软件,在很多场景下面都能派上用场
但是在当前的开源的推理引擎中,即使是兼容OpenAI接口的 Ollama 、 vLLM 和 SGLang 也并不完美
每家实现的兼容OpenAI接口的方式各不相同,这就导致了即使是对 AI 非常熟悉的工程师,也无法完美适配每一家不同的接口
所以针对我们本地部署大模型接入 Claude Code 的场景,我自己写了一个非常轻量级的转换器 local-openai2anthropic
https://github.com/dongfangzan/local-openai2anthropic

这个转换器的设计目标非常简单,只考虑本地部署大模型接入 Claude Code 等编程工具的场景
主要功能:
- 本地部署的 OpenAI 兼容接口(如 SGLang / Ollama / vLLM) 转换成 Anthropic 兼容接口
- 完美适配了不同开源模型的思考、非思考模式的切换
- 通过外接搜索工具,解决本地模型无法进行
WebSearch的问题 - 支持图像输入(
Kimi-K2.5/Qwen3-VL/GLM-4.6V),实现多模态能力 - 完美支持 token 用量估算,避免上下文超限导致的窗口溢出
使用方法
你可以直接通过 pip 安装这个包
pip install local-openai2anthropic
然后通过命令行启动这个转换器
oa2a start
启动后,通过引导输入你的本地 OpenAI 兼容接口地址和 API Key 即可
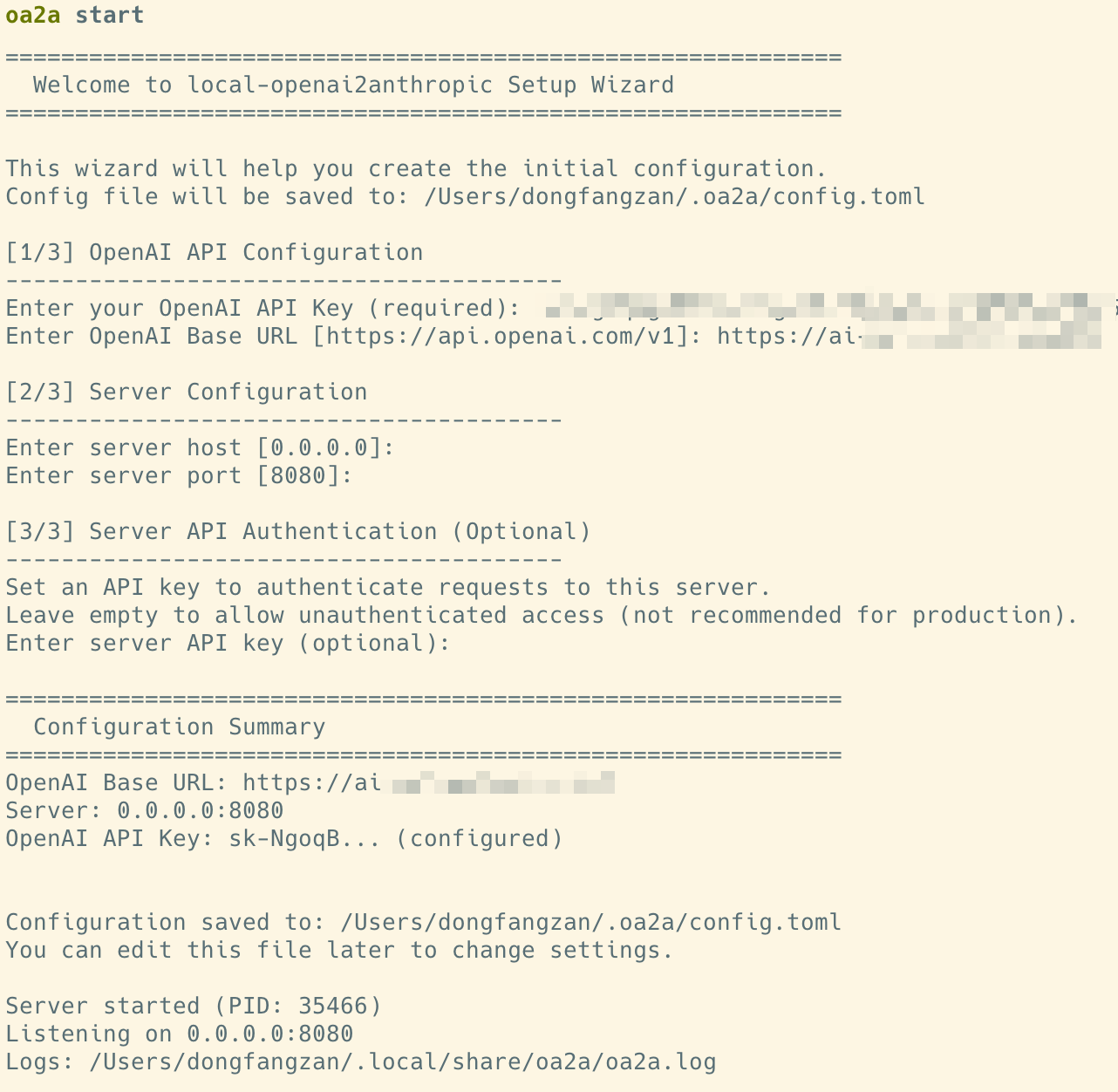
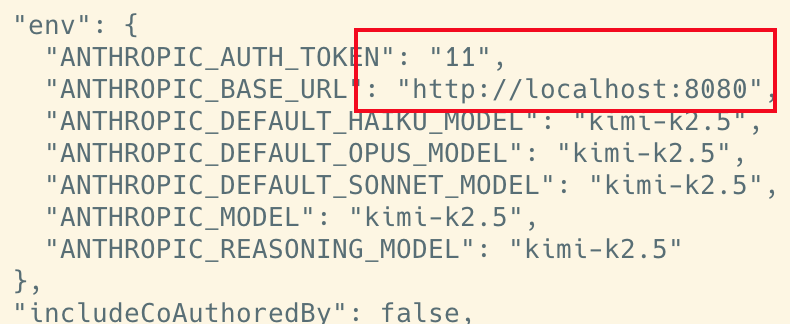
随后,只需要将你Claude Code 的 ANTHROPIC_BASE_URL 地址,指向这个转换器的地址即可
vi ~/.claude_code/settings.json
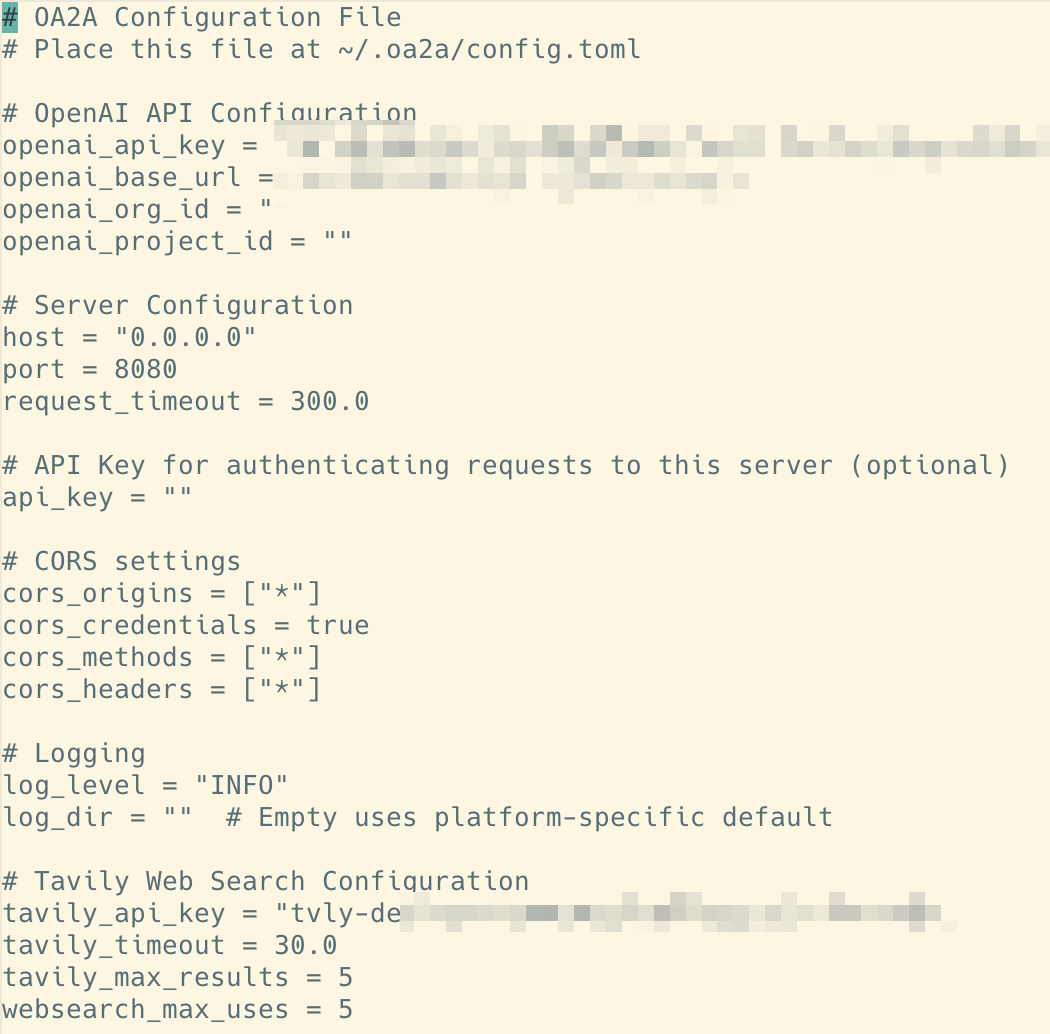
联网搜索支持
如果你需要通过搜索引擎来支持 WebSearch 功能

可以通过配置 tavily_api_key 来实现
vi ~/.oa2a/config.toml
免费版的 Tavily Search,每个月有 1000 次调用额度,基本上可以满足日常使用需求

你可以到他的官网去免费注册一个账号,来获取 API Key
官网地址:https://tavily.com
结束
感谢你看到这里,随着 AI 编程时代的全面到来,本地化部署已经成为追求极致性能与数据隐私开发者的必经之路
目前国产开源模型(如 Kimi-K2.5、GLM-4.7、MiniMax-M2.1)在能力上已经非常能�打,无论你用哪种方式来实现 Vibe Coding,我们的目标都是一致的:
打破格式壁垒,释放本地算力的无限潜力。 🚀
希望这篇教程能帮助你搭建起专属的本地 AI 编程环境,享受不限速、不泄密、不掉线的 Vibe Coding 体验!
如果你在部署过程中遇到任何坑,或者有更好的玩法的,欢迎在评论区交流,或者直接去 GitHub 提 Issue!👋